Isolating Toxic Comments to prevent Cyber Bullying
Online communities are susceptible to Personal Aggression, Harassment, and Cyberbullying.
Affine
AI & AE Team
Online communities are susceptible to Personal Aggression, Harassment, and Cyberbullying. This is expressed in the usage of Toxic Language, Profanity or Abusive Statements. Toxicity is the use of threats, obscenity, insults, and identity based hateful language.
Our objective was to create an algorithm which could identify Toxicity and other Categories with an Accuracy of > 90%. We will now discuss how we created a model with an accuracy of 98%.
Approach Part 1: Engineer the right features for Emotion Capture
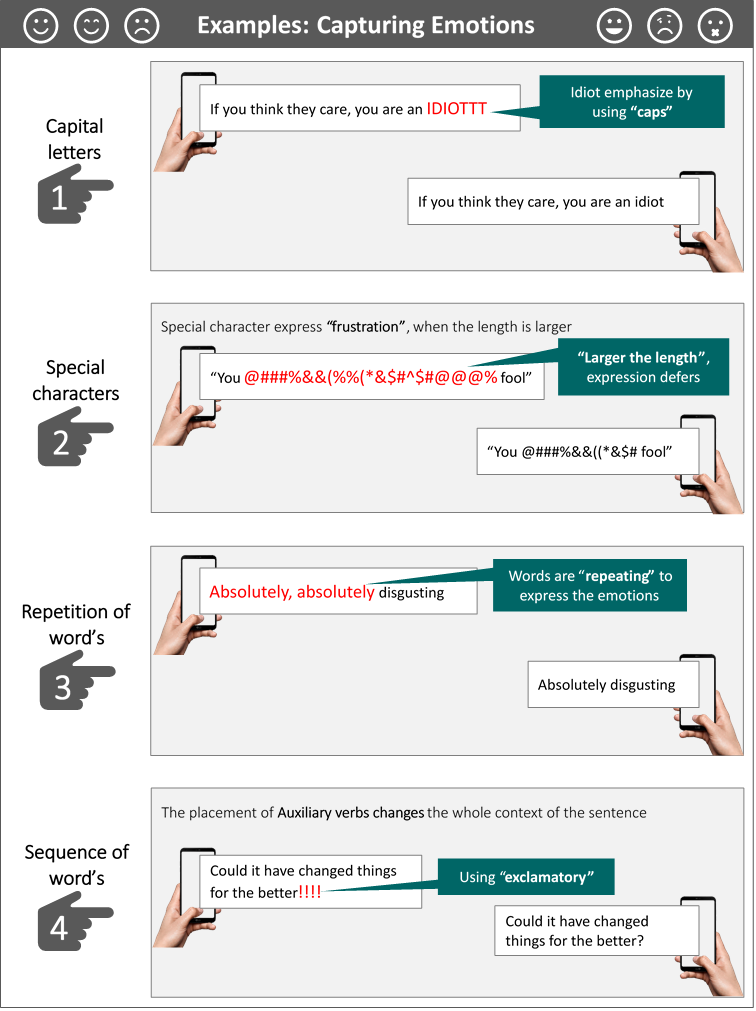
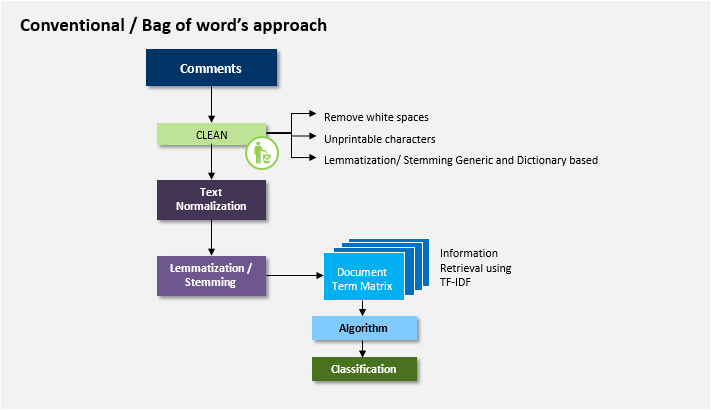
No doubt Toxicity can be detected and measured by the presence of cuss words, obscenities etc. But is that all? Is the bag of words approach which stresses on content alone sufficient enough to define Toxicity? Are we missing information which can be assessed by the sequential nature of language and expression which comes not from the chosen word but also the way it is written or used?
This additional thought process of using Emotion as well as content was validated on the Kaggle Toxic Challenge problem data.
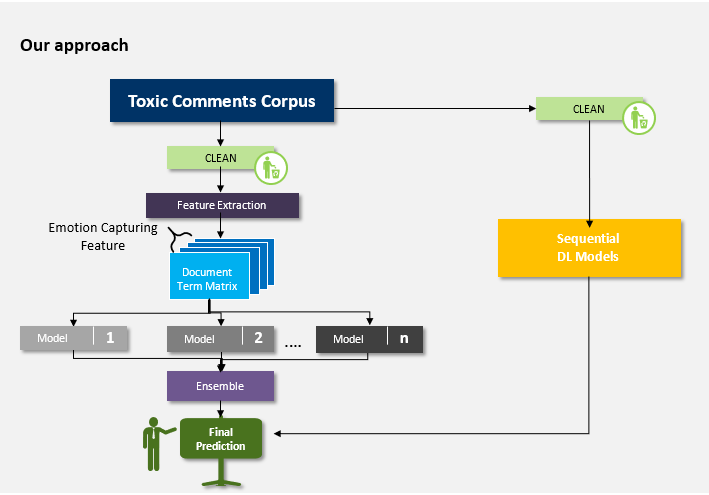
Emotion and Intensity of people’s written comment were captured via Feature Engineering and Deep Learning Models. The content was captured using Machine Learning Models that follow Bag of Words
The inclusion of Emotions coupled with our Ensembling Approach raised the accuracy levels from 60%(Bag of words) to 98%.
Approach Part 2: Create Disparate Models for the best Ensemble
With the Feature Engineering been taken care of, we have the all the information that needed to be extracted from our Corpus. Now the next step which is getting the best possible Ensemble model.
We did a Latent Dirichlet Allocation on the Corpus using the Bag of words approach and we found how some of the Categories were quite similar to another when we saw the Probability Distribution. Categories such as “Toxic”, “Severe Toxic”, “Obscene” which have a small margin of Decision Boundary. This at least confirms that creating one model that predicts all categories may be Time Consuming.
Our Strategy – Come up with the best model for a category. Concentrate on Parameter Tuning of Individual Models. Parameter Tune it till we get the best possible model. Finally, ensemble these models.
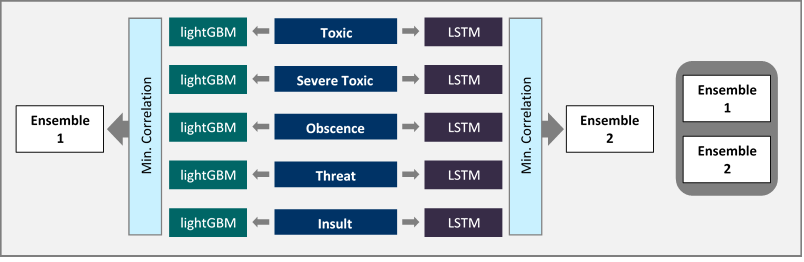
This paved the way for arriving at the best ensemble model as now each of the individual models have less correlations with one another. Also, conceptually we had two classes of Models: The Deep Learning Sequential Models and the Machine Learning Bag of words models. This again contributed to our Ensembling Idea. Meaning there will be certain categories which the Sequential Model will be particularly good at and likewise the Bag of Words Models.
LSTM is a special case of Recurrent Neural Networks. Our Sequential Models consisted of LSTM models each of which were tuned in a manner as to have an edge in predicting one or at most two categories.
Our Bag of words model consisted of Light GBM models. Each of these models with their own different parameters and strengths in a category.
Illustration: As a part of our Ensembling Strategy, Sequential and Bag of Words Models were built for each Toxic Category.
Conclusion: Text Categorization can be dealt efficiently if we combine Bag of Words as well as the Sequential Approach. Also, emotions play a key role in Text Categorization for Classification Problems such as Toxicity.
Contributors
Anshuman Neog: Anshuman is a Consultant at Affine. He is a Deep Learning & Natural Language Processing enthusiast.
Ansuman Chand: Ansuman is a Business Analyst at Affine. His Interests involve real-world implementation of Computer Vision, Machine Intelligence and Cognitive Science. Wishes to actively leverage ML, DL techniques to build solutions.
About Author
Affine is leading AWS select consulting partner renowned for providing cutting-edge cloud services on AWS platform
Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged.