Learn How to Classify Documents Using Computer Vision and NLP

Many companies, especially those in BFSI and Legal sectors, deal with a large volume of handwritten and scanned documents. It is difficult to easily use the granular information in these documents to perform an analysis or even browse through the documents in a convenient manner. A simple classification of the documents into meaningful bins or folders would make it a lot easier to leverage the information within the documents.
The current blog focusses on a Document/Text Classification solution that we developed for an Insurance industry client which focussed on grouping medical/health insurance claims into pre-defined categories. The current process of categorization was done manually by a panel of experts. These experts had their own biasness and heuristics, which lead to inconsistencies.
We developed a Deep Learning based framework which ensembled learnings from document’s layout and structure, the content/text within a given document and amalgamation of consistent & coherent expert opinions. The framework helped in automation of the existing process leading to better efficiency and efficacy.
We had a set of 40k scanned images of medical insurance documents and tried building an algorithm to classify those documents into given 5 categories. These scanned documents exhibited characteristics for each of the classes based on the document structure and token sequences present in the document.
Document Sample:
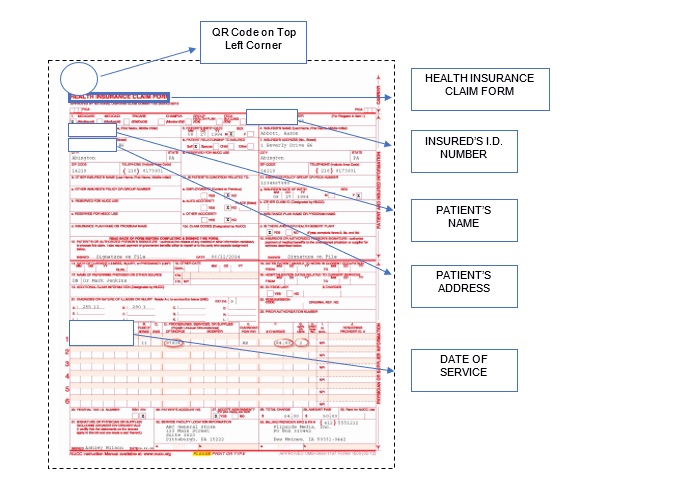
Sample Image Features: Document Structure e.g. QR Code on Top Left Corner, Gridlines etc.
Sample Text Features: Presence of text sequences such as Health Claim Insurance Form, Field information e.g. Insured’s ID Number, Patient’s Name, Patient’s Address, Date of Service etc.
ANALYTICAL APPROACH
Over the past few years, Deep Learning (DL) architectures and algorithms have made impressive advances in fields such as image recognition and speech processing.
Their application to Natural Language Processing (NLP) has now proven to make significant contributions, yielding state-of-the-art results for some common NLP tasks. Named entity recognition (NER), topic modelling and sentiment analysis are some of the problems where neural network models have outperformed traditional approaches.
Convolutional neural networks (CNN) have also been widely used in automatic image classification systems, Object Detection and Recognition, Neural Style Transfer and many more applications. Image classification is the task of taking an input image and outputting a class or a probability of classes that best describes the image.
For the given problem, we decided to use the features of images as well as text in the document. Since these documents were scanned images, the first challenge was to extract text out of them, and second to draw meaningful insights from this text and image. Following is the overall solution architecture:
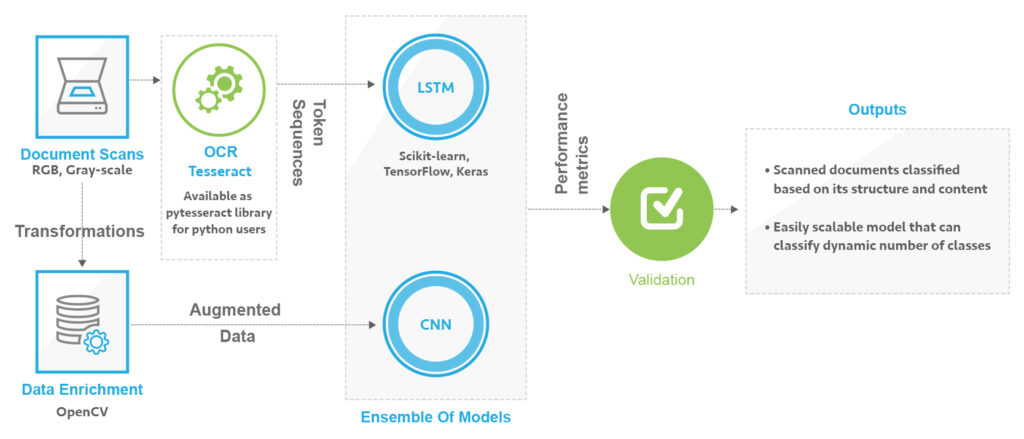
To extract the text sequences out of these images we performed OCR (Optical Character Recognition) using Tesseract. For python users, there is an OCR Library called “pytesseract” with the functionality of “image_to_string” conversion.
CHOICE OF MODEL
Through OCR steps we were able to extract the text sequences out of these scanned images. This leads us to achieve both text and image-based features which were leveraged for developing the classification algorithm.
Bi-directional LSTM:
For text features such as ‘Patient’s Name’, ‘Patient’s Address’, ‘Insured’s ID Number’, ‘Type of Bill’, ‘Patient’s Control Number’ etc. we decided to implement a bidirectional LSTM. Bidirectional LSTMs are an extension of traditional LSTMs that can improve model performance on sequence classification problems. It involves duplicating the first recurrent layer in the network so that there are now two layers side-by-side, then providing the input sequence as-is as input to the first layer and providing a reversed copy of the input sequence to the second.
The text sequences were converted into word vectors using pre-trained Glove embedding vector matrix and then passed through bidirectional LSTM (Long Short-Term Memory) Layer and 2 Dense Layers with ‘ReLU’ and ‘Softmax’ activations respectively.

Convolutional Neural Networks:
To deal with the image features we decided to implement a Convolutional Neural Network.
The image features were extracted and enhanced through 2Convolution layers and 3 dense layers with ReLU activations and softmax for the output layer activations respectively. Data Augmentation was done by flipping these scanned images for adding more features for robustness. Various transformations like resizing, rescaling etc. were also experimented with.

Combination of LSTM & CNN:
A combination of both LSTM and Convolution layers has also experimented on the text features, which resulted in a good classification accuracy.

Ensembling: Ensembling was done to capture features from different models and improve the accuracy of classification. This helped achieve 90% plus overall accuracy in correctly classifying the documents into respective 5 classes.
Please feel free to comment in case of any queries.
Contributors
Shifu Jain: Shifu is a Senior Business Analyst and a part of Affine Artificial Intelligence CoE “AICoE”. Her interests involve exploring and learning new researches in NLP, Topic Modelling, Recurrent Neural Networks etc.
Karthik Devaraj: Karthik is a Consultant at Affine with 6+ years’ experience in the field of Computer Vision, Machine Translation, Generative Algorithms.