Mastering the RAG Architecture

In today’s fast-paced Large Language Models (LLM) landscape, the Retrieval Augmented Generation (RAG) architecture emerges as a game-changer. RAG is a novel architecture that enables the use of LLMs like GPT-3.5/4 or LLAMA to build domain-centric chatbots without the need for expensive fine-tuning. It employs clever techniques to identify relevant contexts from the data, which can then be passed to the LLMs to synthesize answers. While it has been instrumental in several notable production use cases, including our own Eryl product under the GeneraX umbrella, the journey of RAG’s mainstream adoption is only just beginning.
At Affine, we don’t just adopt technology; we sculpt it. We have adopted a scientific approach to harness the capabilities of the RAG architecture for building production-grade LLM customer solutions. This includes our Eryl product, showcasing the manifestation of our philosophy—implementing scientifically engineered solutions that resonate with individual customer requirements.
The RAG’s efficacy pivots around various design parameters. But how does one ensure peak performance? For us, it’s about a rigorous, scientific approach. We have borrowed significantly from the concept of hyperparameter tuning for Machine Learning and Deep Learning models. We systematically navigate these parameters, evaluating their performance on real-world test data – such as customer interactions in chat sessions that have received high Net Promoter Score (NPS) ratings, an industry-standard metric for customer satisfaction.
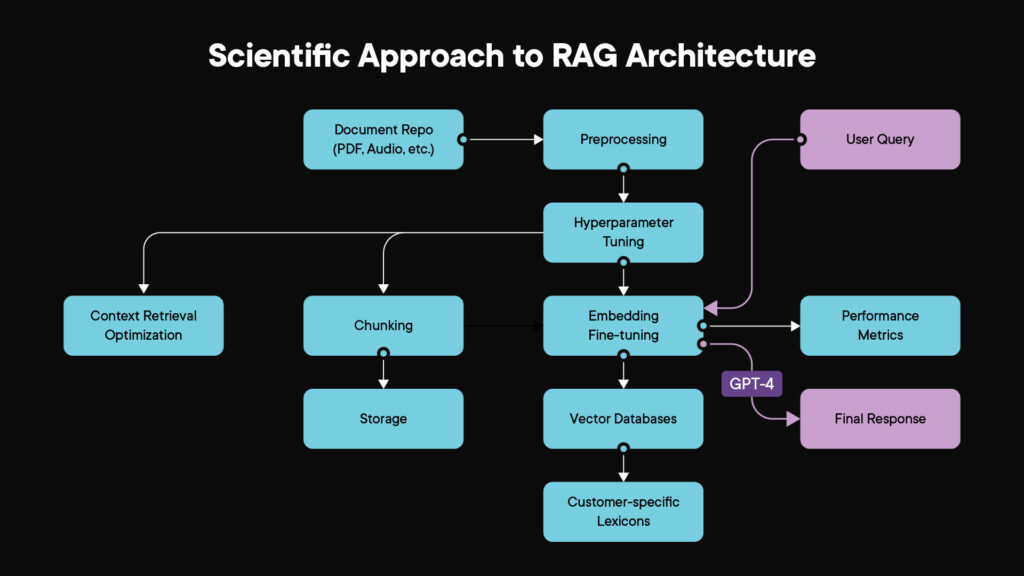
When it comes to building scalable, production-grade, and hallucination-free LLM applications, the key objectives are not only the accuracy of outputs but also factors like latency and cost of inferences. We evaluate the performance of all hyperparameters on all these factors and select or fine-tune iterations that rate high across all success factors.
Listed below are some RAG hyperparameters we utilize while developing LLM applications:
- Chunk Management Related: At the heart of RAG’s contextual retrieval lies a matrix of parameters – chunk size, overlap window, and top K chunks for retrieval (meaning the top K most relevant text chunks that are retrieved). Much like deep learning tuning, we employ an iterative but optimized methodology to discern the most effective combination.
- Embedding Model Fine-tuning: Fine-tuning the embedding model ensures the domain specificity of embeddings, thereby allowing retrieval of relevant chunks from the vector databases.
- Generator LLM Fine-tuning: By refining the synthesizer LLM on specific customer documents, it becomes attuned to unique nomenclatures and keywords. Given that this LLM steers the response synthesis, generating the final text that the end-users interact with, alignment with customer-specific lexicons is pivotal.
- Enhancement with Knowledge Graphs: Incorporating Knowledge Graphs with RAG becomes a force multiplier, especially for intricate, multi-contextual, or multi-hop queries, where the model needs to consider multiple factors or steps to generate an accurate response.
- Hard cutoff on Cosine Similarity: The conventional method of selecting Top K embeddings may still result in hallucinations, as for certain queries, none of the top K chunks may be relevant. In such cases, it is essential to have a hard cutoff on cosine similarity that only fetches chunks above the threshold.
Our approach involved systematically iterating through various combinations of the above design parameters in an optimized fashion and evaluating the performance on test data. It should be noted that iterations involving fine-tuning embeddings or generator LLM models can be computationally expensive and should be undertaken only if the development budget allows.
The following capture key performance metrics and other ML/LLM hygiene practices that we adopt in building the LLM application:
- Performance Metrics: Our benchmarking isn’t just about accuracy. By analyzing real human chat logs with high NPS scores, we gauge efficacy. Additionally, parameters like latency and cost of inferences help construct a system that’s precise, economical, and prompt.
- Optimization within Boundaries: Despite the computational complexity, especially when fine-tuning the embedding and generator models, we ensure that development remains within budget constraints, thus achieving a balance between performance and cost.
- Systematic Record-Keeping with MLOps: Tools like MLflow are invaluable, enabling us to meticulously document all iterations, providing a robust framework for tracking changes, and ensuring that the model can be easily deployed or rolled back as needed.
The culmination of these steps results in an LLM solution that’s not only primed for production but also accurate, cost-effective, and systematically built, ensuring reproducibility and reusability.
In summary, the RAG architecture isn’t merely an innovation in building QnA systems; it’s a game-changer in the realm of large language models. By enabling specialized chatbots to leverage the power of LLMs without the need for expensive fine-tuning, our Eryl product exemplifies how the intelligent use of LLMs, enabled by RAG, can yield a product that is not only cutting-edge but also finely tuned to meet distinct customer needs.
At Affine, we don’t merely adapt to technology; we shape it, refine it, and make it our own. We continually integrate groundbreaking technology into our ethos of delivering scientifically engineered solutions, creating products that are not just innovative but also tailor-made to tackle real-world business challenges head-on.
As we continue to advance in this journey, the RAG architecture stands as a cornerstone, showcasing the incredible potential and adaptability rooted in the synergy between retrieval and generation techniques in LLMs. We aim to go beyond just building chatbots; our vision is to build intelligent systems that can understand, learn, and adapt, setting new standards for what is achievable in the realm of artificial intelligence.