TensorFlow Lite: The Future of AI in Mobile Devices

Do you use Google Services on your mobile phones? If so, you would have probably noticed that the predictive capability of this service has recently improved with respect to speed and accuracy. The enhanced predictive capability of Google is now faster, thanks to TensorFlow Lite working with your phone’s GPU.
What is TensorFlow Lite?
TFLite is TensorFlow’s light weight solution for mobile, embedded and other IoT devices. It can be described as a toolkit that helps developers run the TensorFlow model on such devices.
What is the need for TensorFlow Lite? Running Machine Learning models on mobile devices are not easy due to the limitation of resources like memory, power, storage, etc. Ensuring that the deployed AI models are optimized for performance under such constraints becomes a necessary step in such scenarios. This is where the TFLite comes into the picture. TFLite models are hyper-optimized with model pruning and quantization to ensure accuracy for a small binary size with low latency, allowing them to overcome limitations and operate efficiently on such devices.
TensorFlow Lite consists of two main components:
- The TensorFlow Lite converter: that converts TensorFlow models into an efficient form and creates optimizations to improve binary size and performance.
- The TensorFlow Lite interpreter: runs the optimized models on different types of hardware, including mobile phones, embedded Linux devices, and microcontrollers.
TensorFlow Lite Under the Hood
Before deploying the model on any platform, the trained model needs to go through a conversion process. The diagram below depicts the standard flow for deploying a model using TensorFlow Lite.
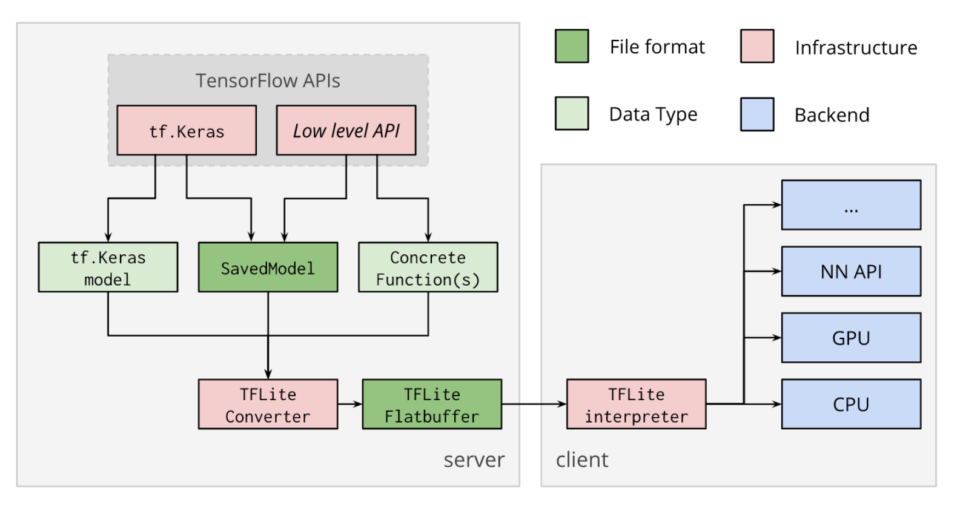
Fig: TensorFlow Lite conversion and inference flow diagram.
Step 1: Train the model in TensorFlow with any API, for e.g. Keras. Save the model (h5, hdf5, etc.)
Step 2: Once the trained model has been saved, convert it into a TFLite flat buffer using the TFLite converter. A Flat buffer, a.k.a. TFLite model is a special serialized format optimized for performance. The TFLite model is saved as a file with the extension .tflite
Step 3: Post converting the TFLite flat buffer from the trained model, it can be deployed to mobile or other embedded devices. Once the TFLite model gets loaded by the interpreter on a mobile platform, we can go ahead and perform inferences using the model.
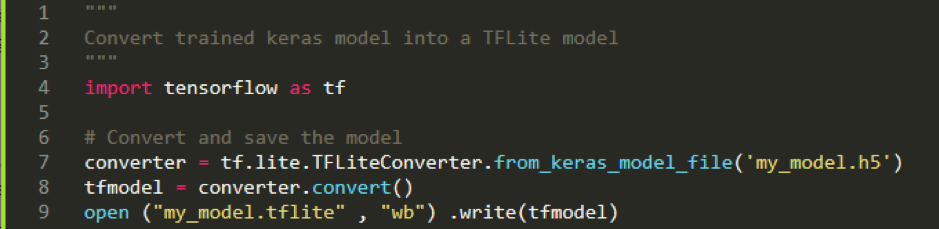
Converting your trained model (‘my_model.h5’) into a TFLite model (‘my_model.tflite’) can be done with just a few lines of code as shown below:
How does TFLite overcome these challenges?
TensorFlow Lite uses a popular technique called Quantization. Quantization is a type of optimization technique that constrains an input from a large set of values (such as the real numbers) to a discrete set (such as the integers). Quantization essentially reduces the precision representation of a model. For instance, in a typical deep neural network, all the weights and activation outputs are represented by a 32-bit floating-point numbers. Quantization converts the representation to the nearest 8-bit integers. And by doing so, the overall memory requirement for the model reduces drastically which makes it ideal for deployment in mobile devices. While these 8-bit representations can be less precise, certain techniques can be applied to ensure that the inference accuracy of the new quantized model is not affected significantly. This means that quantization can be used to
make models smaller and faster without sacrificing accuracy. Stay tuned for the follow up blog that will be a walkthrough of how to run a Deep learning model on a Raspberry Pi 4. In the meantime, you can keep track of all the latest additions to TensorFlow Lite at https://www.tensorflow.org/lite/