Capsule Network: A step towards AI mimicking human learning systems

1. A quick introduction to Convolution Neural Networks
The field of computer vision has witnessed a paradigm shift after the introduction of Convolutional Neural Network (CNN) architectures which has pushed AI performance at par with humans. There has been significant progress in CNN driven architectures right from the first AlexNet architecture published in 2012 to newer architectures like ResNet, DenseNet, NASNet and more recently EfficientNet; each focusing on improving accuracy while rationalizing the computing cost of adoption (through a lesser number of parameters).
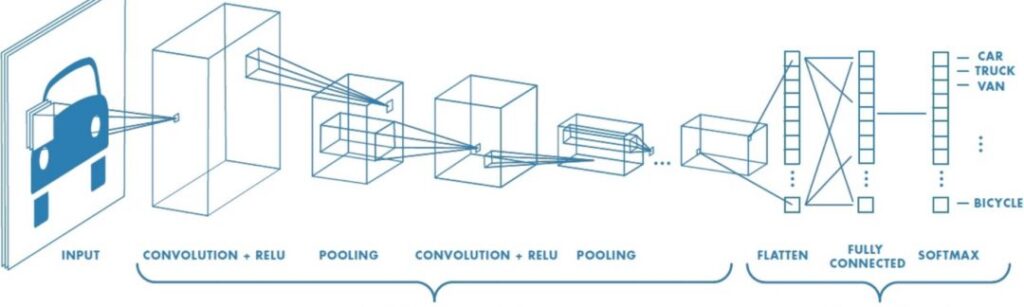
An Illustration of CNN architecture
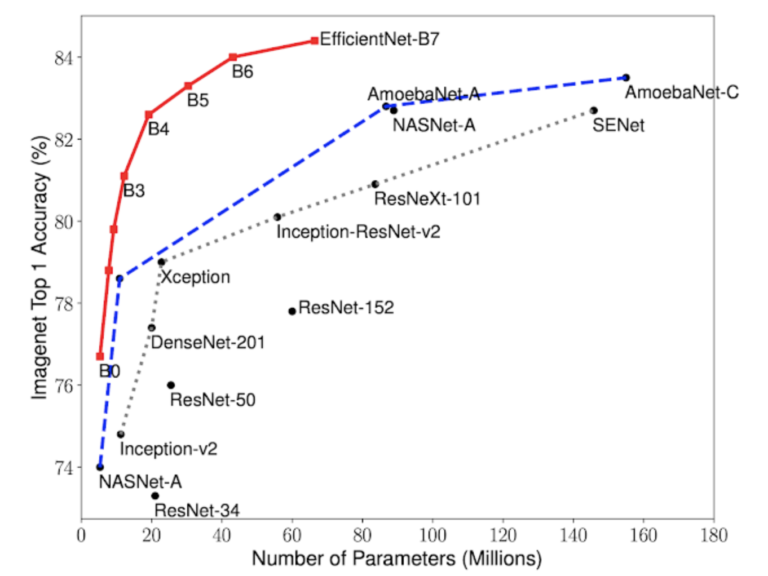
Evolution of various CNN architectures Ref: https://arxiv.org/pdf/1905.11946.pdf
CNNs learn faster with higher accuracy than any traditional non-convolutional image models owing to features like :
- Local connectivity: While this limits the learnings to nearby pixel but it is sufficient enough to learn correlations required to evaluate an image
- Parameter sharing across spatial locations: It makes learning easier and faster by reducing redundancy. e.g. if the algorithm has learned to detect horizontal edge at a point A, it need not learn horizontal edge detection again at point B
2. Drawbacks of CNN
While CNN has worked remarkably well, they fall short on 2 key aspects: Lack of Invariance: Human beings perceive in a translation invariance way, which means we are capable of identifying an object even if the location and orientation of the object changes in our field of view. An example below:

Humans can identify cat in each of the above scenarios. However, CNN needs to be trained on multiple orientation scenarios for accurate inferencing. While image augmentation techniques have helped to overcome the orientation challenge, but it leads to higher processing, data management costs and also might not work in all scenarios.
Loss of information on related features: Image Source
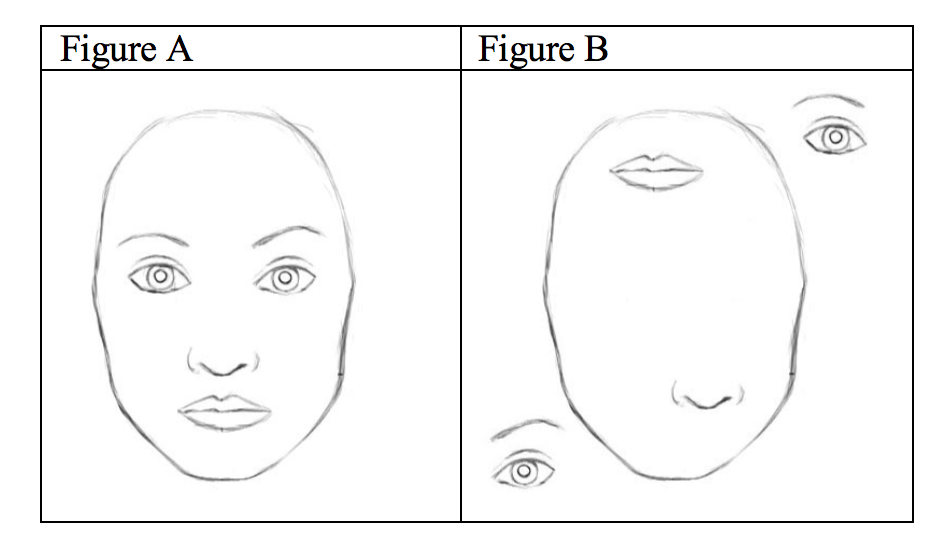
In the scenario above, CNN will recognize both Figures A and B as a face.
This happens due to the Pooling layers in the CNN architecture. In simple terms, we know that initial layers in CNN learn about the low-level features e.g. edges, points, curves, arcs, etc., while the later layers learn about high-level features e.g. eyes, nose, lips which are further enhanced to identify the actual object i.e. the human face in subsequent layers. The intermediate Pooling layers help in regulating these high order features while reducing the spatial size of the data flowing through the network. The dynamics of Pooling layers don’t take into account the spatial relationships between simple and complex objects.
Thus, in both Figure A and B, CNN recognizes a face by evaluating the presence of high-level features like eyes, nose, lips, without applying any cognizance to their spatial relationships.
3. How can Capsule Network address the problem?
According to Hinton, for accurate image classification CNN should be able to learn and preserve the spatial relationships and hierarchies between the features. Capsule networks, introduced by Hinton and his team, is a step towards learning a better and complete knowledge representation.
What is a capsule? A capsule is a group of neurons that captures both the likelihood and parameters of the specific feature Capsule networks use a vector representation as compared to scalar representations used in existing neurons in CNN architectures. This capsule vector representation includes (1) whether an object exists (2) what are the key features (3) where is it located. Thus, for an object capsule, the activations will consist of: 1. Presence probability ak 2. Feature vector ck 3. Pose matrix OVk which represents the geometrical relationship between the object and its parts thus able to infer various feature orientations and hierarchies
Capsule networks will also be able to identify abstract version of the objects even if it has not been trained on the particular image, an example below:

Capsule networks will be able to identify Image2 with moderate accuracy even if it hasn’t been part of its training image. This is not possible with the regular CNN architectures.
4. What is the current status in Capsule Networks research?
Few popular techniques for implementing a capsule architecture has been discussed below:
A. Dynamic Routing Algorithm (source)
The original Capsules network developed by Hinton and his team uses a Dynamic routing algorithm to group child capsules to form a parent capsule. The vectors of an input capsule are transformed to match the output, and if a close match is available it forms a vote, capsules with a similar vote are grouped.
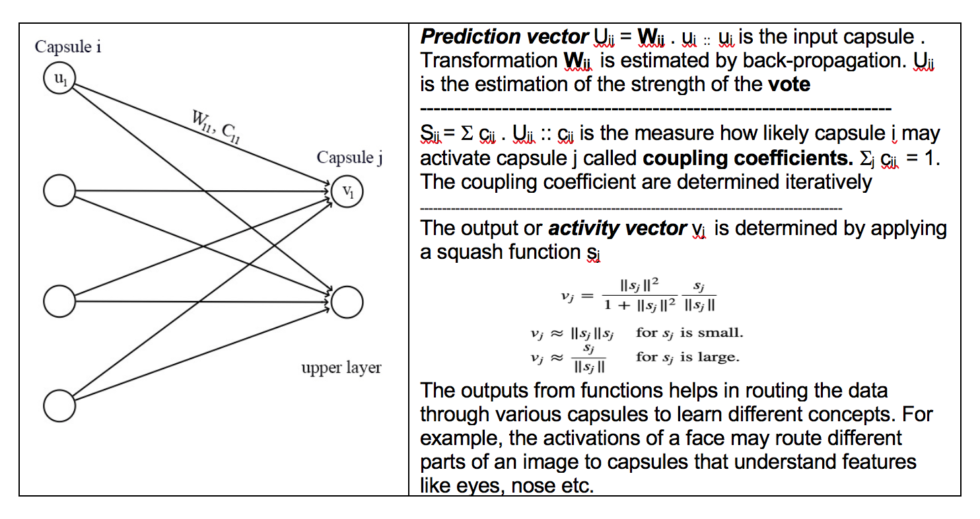
If the activity vector has a close similarity with the prediction vector, then both capsules are inferred to be related to each other. The main drawback of this approach is that it takes a long time both during training and inferencing of the model. Since the voting is done iteratively, each part could start by initially disagreeing and voting on different objects, before converging to the relevant object. Hence this iterative manner of voting is highly time consuming and inefficient
B. Stacked Capsule Autoencoders (SCAE) (source)
Dynamic routing can be thought of a bottom-up approach where the parts are used to learn parts à object relationship. Since this relationship is learnt in an iterative manner (iterative routing) it leads to many inefficiencies. SCAE takes a top-down approach where parts of a given object are predicted, thus removing the dependency of the iterative routing approach. A further advantage of this version of capsules is that it can perform unsupervised learning.
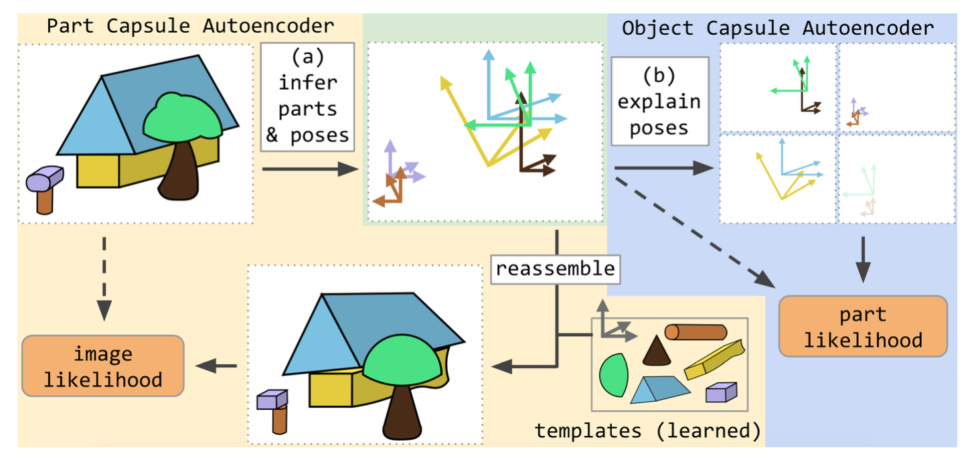
SCAE consists of two networks
- 1. Part Capsule Autoencoder (PCAE) : Detects parts and recombines them into an image in the following manner
- Part Capsule Encoder: Segments an image into constituent parts, infers their poses
- Part Capsule Decoder: Learns an image template for each part and reconstructs each image pixel
2. Object Capsule Autoencoder (OCAE), organizes parts into objects
- Object Capsule Encoder: Tries to organize discovered parts and their poses into a smaller set of objects
- Object Capsule Decoder: Make predictions for each object part into one of the object types
Capsule Networks has achieved better performance as compared to CNN networks on MNIST (98.5% to 99%) and SVHN datasets (55% to 67%). The major drawback of SCAE is that the part decoder uses fixed templates, which are insufficient to model complicated real-world images. These networks can be perceived as a network with reasoning ability and thus with more expressive templates in the future, it can help infer complex real-world images efficiently with lesser data.