Data Augmentation For Deep Learning Algorithms

Plentiful high-quality data is the key to great deep learning models. But good data doesn’t come easy, and that scarcity can impede the development of a good model. It’s relatively easy for a model to identify things from an image when everything is ‘Just Right’ —the correct illumination and zoom level, the right perspective etc. But when the images are not so ideal, the model struggles to give a reasonable prediction. So typically, one would want to train a network with images which are ‘not so ideal’ to help it predict better. But how do you get such data? Well, you basically fake it by taking a regular image and using data augmentation.
Smart approaches to programmatic data augmentation can increase the size of your training set 10-fold or more. Even better, your model will often be more robust (and prevent overfitting) and can even be simpler due to a better training set. What you are trying to do is teach your neural network about something called invariance, which is basically the ability to recognize (“classify”) the object regardless of the conditions that it is presented in —conditions like size, viewpoint, illumination, and translation.
To generate augmented data libraries like Augmentor and imgaug could be used. These Python packages are designed to aid the artificial generation of image data for machine learning tasks. Below are a few examples (and not an exhaustive list) of the different augmentations you can try out when training a model.
Black and White
This augmentation converts the image into a black-white image. It helps in making the model invariant to colour.

Brightness
Brightness augmentation helps in simulating day or night scenarios in images. This improves the model’s prediction in differently lit scenes.

Contrast
This augmentation enhances the contrast of the image and can help in proper differentiation between different features in an image.

Flip Random
Flipping the image vertically or horizontally helps a model become invariant to orientations and positions of the objects in an image.

Gamma Adjustment
This augmentation controls the luminance of an image.

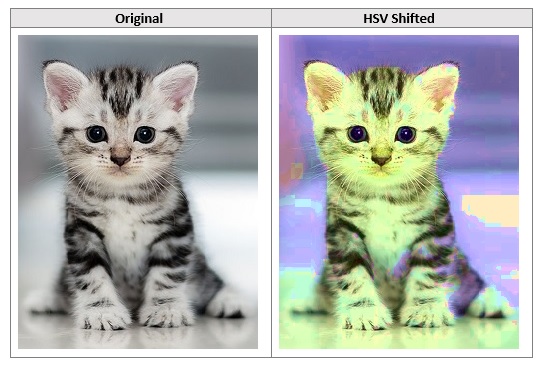
HSV Shifting
This augmentation shifts the hue channel of an image and should help the network become colour invariant.
Rotate without crop
The rotation augmentation makes the network invariant to orientation of objects in the image.

Rotate with crop
Unlike Rotate without crop (previous augmentation), you don’t get ‘black areas’ on the sides of the image and is the preferred approach for semantic segmentation tasks.

Random Distortion
This method is useful when you need to predict objects that don’t have a fixed shape. For example, detecting water bodies from satellite images etc.

Random Erasing
Random erasing selects a rectangle region in an image and erases its pixels with random values. This helps the network predict correctly even when part of the object is occluded.

Skew Tilt
This augmentation tilts the image in a random direction by an arbitrary amount. This helps with predictions when the object is viewed from different angles.

Salt and Pepper Noise
This technique adds artificial noise to the image. It is used to prevent a model from learning high frequency features that may not be useful and helps prevent over fitting.

Shear
This augmentation shears the image by an arbitrary amount.

Rain
This augmentation adds artificial rain in the image and is used widely to train autonomous driving models.

Zoom
This augmentation zooms in an image by an arbitrary amount. It helps the network invariant to size and also to predict well when part of the object is not in the image.

Polygon Shadow
This augmentation creates artificial shadows in images. This technique is frequently used in training self-driving car models.

Now that we have seen few of the augmentation techniques, a question that may arise is, how do you make sure that a data augmentation technique is going to be relevant for you? Well, you typically do that manually - you figure out what the problem space is, the possible scenarios and pick and choose.
The problem with this approach is that we all have biases, conscious or otherwise. These could be something as simple as incorrect assumptions. These biases, along with the fact that this is still an evolving field, and we just don’t know what and how much augmentation to optimally do, result in a lot of guesswork.
However, all hope is not lost, and you should know there is some excellent work being done out there in figuring out the optimal data augmentation strategy for a given problem. Google, for example, has released AutoAugment, where they use Reinforcement Learning to figure out which combination of data augmentation techniques works best for your specific problem space and dataset.
Hope this article shed some light on image data augmentation for deep learning. If you have any questions, you can send me an email at balu.nair@affine.ai