Deep Learning Demystified 2: Dive Deep into Convolutional Neural Networks

The above photo is not created by a specialized app or photoshop. It was generated by a Deep learning algorithm which uses convolutional networks to learn artistic features from various paintings and changes any photo depicting how an artist would have painted it.
Convolutional Neural Networks has become part of every state of the art solutions in areas like
- Image recognition
- Object Recognition
- Self-driving cars in identifying pedestrians, objects.
- Emotion recognition.
- Natural Language Processing.
A few days back Google surprised me with a video called Smiles 2016 where all the photos of 2016 where I was partying with family, friends, colleagues are put together. It was a collection of photos where everyone in the photo was smiling. Emotion recognition. We will discuss a couple of Deep learning architectures that powers these applications in this blog.
Before we dive into CNN lets try to understand why not Feed Forward Neural network. According to universality theorem which we discussed in the previous blog, any network will be able to approximate a function just by adding Neurons(Functions), but there are no guarantees in time when will it reach the optimal solution. Feed Forward neural networks tend to flatten images to a flat vector thus losing all the spatial information that comes with an Image. So for problems where spatial feature importance is high CNN tend to achieve higher accuracy in a very shorter time compared to Feed-Forward Neural Networks.
Before we dive into what a Convolutional Neural Network is letting get comfortable with nuts and bolts which form it.
Images
Before we dive into CNN lets take a look at how a computer looks at an image.


Wow, it’s great to know that computer sees images, videos as a matrix of numbers. A common way of looking at an image in computer vision is a matrix of dimensions Width * Height * Channels. Where Channels are Red, Green, Blue and sometimes alpha is also part of channels.
Filters
Filters are a small matrix of numbers usually of size 3*3*3 (width, height, channel) or 7*7*3. Filters perform various operations like blur, sharpen, outline on a given image. Historically these filters are carefully hand picked to gain various features of an image. In our case, CNN creates these filters automatically using a combination of techniques like Gradient descent and Backpropagation. Filters are moved across an image starting from top left to the bottom right to capture all the essential features. They are also called as kernels in Neural networks.
Convolutional
In a convolutional layer, we convolve the filter with patches across an image. For example on the left-hand side of the below image is a matrix representation of a dummy image and the middle layer is the filter or kernel. The right side of the image has the output of convolution layer. Look at the formula in the image to understand how the kernel and a part of the image are combined together to form a new pixel.
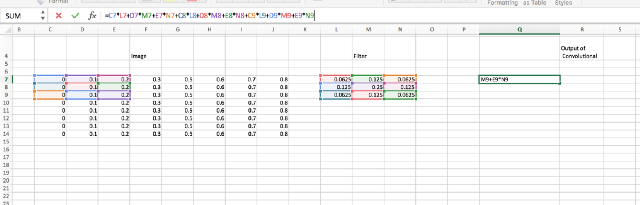
Let’s see another example of how the next pixel in the image is being generated.
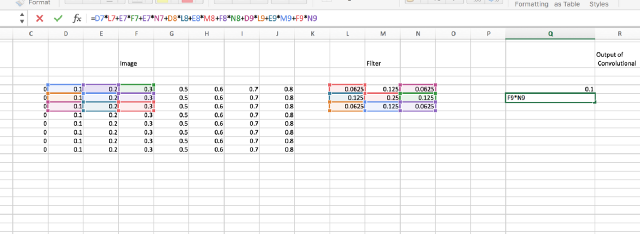
Max-Pooling
Max pooling is used for reducing dimensionality and down-sampling an input. The best way to understand Max-pooling is an example. The below image describes what a 2*2 Max pooling layer does.
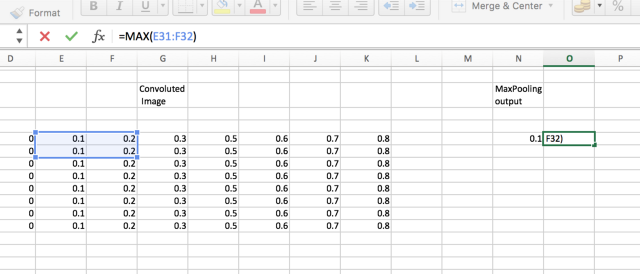
In both the examples for convolution and Max-pooling, the image shows for only 2 pixels, but in reality, the same technique is applied to the entire image.
Now with an understanding of all the important components, let’s take a look at how the Convolutional Neural Network looks like.
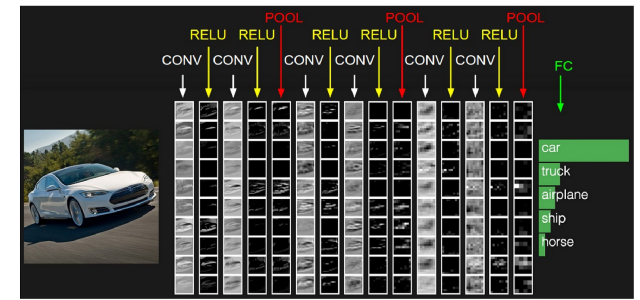
As you can see from the above image, a CNN is a combination of layers stacked together. The above architecture can be simply depicted as CONV-RELU-CONV-RELU_POOL * 3 + Fully connected Layer.
Challenges
Convolutional Neural Networks need huge amounts of labeled data and lots of computation power to get trained. They typically take weeks to get trained to achieve state of the art performance. Most of these architectures like AlexNet, ZF Net, VGG Net, Google Net, Microsoft Res Net take weeks to get trained. Does that mean, an organization without huge volumes of data and computation power cannot take advantage of it? The answer is No.
Transfer Learning to the Rescue
Most of the winners of the ILSVRC (ImageNet Large-Scale Visual Recognition Challenge) competition has open sourced the architecture and the weights associated with these networks. It turns out, most of the weights particularly that of the filters can be reused after fine tuning to the domain specific problems. So for us to take advantage of these convolutional neural networks, all we need to do is pre-train the last few layers of the network. Which in general takes very little data and computation powers. For several of our scenarios, we were able to train models with state of art performance on GPU machines in few minutes to hours.
Conclusion
Apart from use cases like image recognition , CNN is being widely used in various network topology’s like object recognition (What objects are located in images), GAN (A recent breakthrough in helping computers create realistic images), converting low resolution images to high resolution images , in revolutionizing health sector in various forms of cancer detection and many more. In recent months there were architectures built for NLP achieving state of art results.