Hotel Recommendation Systems: What is it and how to effectively build one?

What is a Hotel Recommendation System?
A hotel recommendation system aims at suggesting properties/hotels to a user such that they would prefer the recommended property over others.
Why is a Hotel Recommendation System required?
In today’s data-driven world, it would be nearly impossible to follow the traditional heuristic approach to recommend millions of users an item that they would actually like and prefer.
Hence, a Recommendation System solves our problem where it incorporates user’s input, historical interaction, and sometimes even user’s demographics to build an intelligent model to provide recommendations.
Objective:
In this blog, we will cover all the steps that are required to build a Hotel Recommendation System for the problem statement mentioned below. We will do an end-to-end implementation from data understanding, data pre-processing, and the algorithms used along with their PySpark codes.
Objective: Build a recommendation system providing hotel recommendations to users for a particular location they have searched for on xyz.com
What type of data are we looking for?
Building a recommendation system requires two sources of data, explicit and implicit signals.
Explicit data is the user’s direct input, like filters (4 star rated hotel or preference of pool in a hotel) that a user applies while searching for a hotel. Information such as age, gender, and demographics also comes under explicit signals.
Implicit data can be obtained by users’ past interactions, for example, the average star rating preferred by the user, the number of times a particular hotel type (romantic property) is booked by the user, etc.
What data are we going to work with?
We are going to work with the following:
- Explicit signals where a user provides preferences for what type of amenities they are looking for in a property
- Historical property bookings of the user
- Users’ current search results from where we may or may not get information regarding the hotel that a user is presently interested in
Additionally, we have the property information table (hotel_info table), which looks like the following:

hotel_info table
Note: We can create multiple property types (other than the above 4, Wi-Fi, couple, etc.) ingeniously covering the maximum number of properties in at least one of the property types. However, for simplicity, we will continue with these 4 property types.
Data Understanding and Preparation:
Consider that the searches data is in the following format:

user_search table
Understanding user_search table:
Information about a user (user ID), the location they are searching in (Location ID), their check-in and check-out dates, the preferences applied while making the search (Amenity Filters), the property specifically looked into while searching (Property ID), and whether they are about to book that property (Abandoned cart = ‘yes’ means that they are yet to make the booking and only the payment is left) can be extracted from the table
Clearly, we do not have all the information for the searches made by the user hence, we are going to split the users into 3 categories; namely, explicit users (users whose amenity filter column is not null), abandoned users (users whose abandoned cart column is ‘yes’), and finally, historical users (users for whom we have historical booking information)
Preparing the data:
For splitting the users into the 3 categories (explicit, abandoned, historical), we give preference in the following order, Abandoned users>Explicit users>historical users. This preferential order is because of the following reasons:
The abandoned cart gives us information regarding the product the user was just about to purchase. We can exploit this information to give recommendations similar to the product in the cart; since the abandoned product represents what a user prefers. Hence, giving abandoned users the highest priority.
An explicit signal is an input directly given by the user. The user directly tells his preference through the Amenities column. Hence, explicit users come next in the order.
Splitting the users can be done following the steps below:
Firstly, create a new column as user_type, under which each user will be designated with one of the types, namely, abandoned, explicit, or historical
Creating a user_type column can be done using the following logic:
df_user_searches = spark.read.parquet(‘xyz…….’)
df_abandon = df_user_searches.withColumn(‘abandon_flag’,F.when(col(‘Abandon_cart’).like(‘yes’) & ‘Property_ID is not Null’,lit(1)).otherwise(lit(None))).filter(‘abandon_flag = 1’).withColumn(‘user_type’,lit(‘abandoned_users’)).drop(‘abandon_flag’)
df_explicit = df_user_searches.join(df_abandon.select(‘user_ID’),’user_ID’,’left_anti’).withColumn(‘expli_flag’,F.when(col(‘Amenity_Filters’).like(‘%Wifi Availibility%’)|col(‘Amenity_Filters’).like(‘%Nature Friendly%’)|col(‘Amenity_Filters’).like(‘%Budget Friendly%’)|col(‘Amenity_Filters’).like(‘%Couple Friendly%’),lit(1)).otherwise(lit(None))).filter(‘expli_flag = 1’).withColumn(‘user_type’,lit(‘explicit_users’)).drop(‘expli_flag’)
df_historical = df_user_searches.join(df_abandon.unionAll(df_explicit).select(‘user_ID’).distinct(),’user_ID’,’left_anti’).withColumn(‘user_type’,lit(‘historical_user’))
df_final = df_explicit.unionAll(df_abandon).unionAll(df_historical)
Now, the user_search table has the user_type as well. Additionally,
For explicit users, user_feature columns will look like this:

explicit_users_info table
For abandoned users, after joining the property id provided by the user with that in the hotel_info table, the output will resemble as follows:

abandoned_users_info table
For historical users, sum over the user and calculate the total number of times the user has booked a particular property type; the data will look like the following:

historical_users_info table
For U4 in the historical_users_info table, we have information that tells us that the user prefers an average star rating of 4, has booked WiFi property 5 times, and so on. Eventually, telling us the attribute preferences of the user….
Building the Recommendation System:
Data at hand:
We have users split and user’s preferences as user_features
We have the hotel attributes from the hotel_type table, assume that it contains the following values:
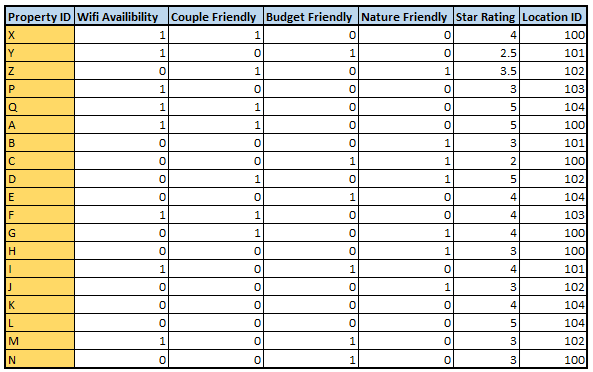
hotel_type table
We will use content-based-filtering in building our recommendation model. For each of the splits, we will use an algorithm that will give us the best result. To gain a better understanding of recommendation systems and content-based filtering, one can refer here.
Note: We have to give recommendations based on the location searched by the user. Hence, we will perform a left join on the key Location ID to get all the properties that are there in the location.
Building the system:
For Explicit users, we will proceed in the following way:
We have user attributes like wifi_flag, budget_flag, etc. Join this with the hotel_type table on the location ID key to get all the properties and their attributes
Performing Pearson correlation will give us a score([-1,1]) between the user and hotel features, eventually helping us to provide recommendation in that location
Code for explicit users:
explicit_users_info = explicit_users_info.drop(‘Property_ID’)
expli_dataset = explicit_users_info.join(hotel_type,[‘location_ID’],’left’).drop(‘star_rating’)
header_user_expli = [‘wifi_flag’,’couple_flag’,’budget_flag’,’nature_flag’]
header_hotel_features = [‘Wifi_Availibility’,’Couple_Friendly’,’Budget_Friendly’,’Nature_Friendly’]
assembler_features = VectorAssembler(inputCols= header_user_expli, outputCol=”user_features”)
assembler_features_2 = VectorAssembler(inputCols= header_hotel_features, outputCol=”hotel_features”)
tmp = [ assembler_features,assembler_features_2]
pipeline = Pipeline(stages=tmp)
baseData = pipeline.fit(expli_dataset).transform(expli_dataset)
df_final = baseData
def pearson(a,b):
if (np.linalg.norm(a) * np.linalg.norm(b)) !=0:
a_avg, b_avg = np.average(a), np.average(b)
a_stdev, b_stdev = np.std(a), np.std(b)
n = len(a)
denominator = a_stdev * b_stdev * n
numerator = np.sum(np.multiply(a-a_avg, b-b_avg))
p_coef = numerator/denominator
return p_coef.tolist()
pearson_sim_udf = udf(pearson, FloatType())
pearson_final = df_final.withColumn(‘pear_correlation_res’, pearson_sim_udf(‘user_features’,’hotel_features’))
pearson_final.withColumn(‘recommendation_rank’,F.row_number().over(Window.partitionBy(‘User_ID’).orderBy(desc(‘pear_correlation_res’)))).show()
Our output will look like the following:

explicit users
For abandoned and historical users, we will proceed as follows:
Using the data created above, i.e., abandoned_users_info and historical_users_info tables, we obtain user preferences in the form of WiFi_Availibility or wifi_flag, star_rating or avg_star_rating, and so on
Join it with the hotel_type table on the location ID key to get all the hotels and their attributes
Perform Cosine Similarity to find the best hotel to recommend to the user in that particular location
Code for abandoned users:
abandoned_users_info = abandoned_users_info.drop(‘Property_ID’)\
.withColumnRenamed(‘Wifi_Availibility’,’a_Wifi_Availibility’)\
.withColumnRenamed(‘Nature_Friendly’,’a_Nature_Friendly’)\
.withColumnRenamed(‘Budget_Friendly’,’a_Budget_Friendly’)\
.withColumnRenamed(‘Couple_Friendly’,’a_Couple_Friendly’)\
.withColumnRenamed(‘Star_Rating’,’a_Star_Rating’)
abandoned_dataset = abandoned_users_info.join(hotel_type,[‘location_ID’],’left’)
header_user_aban = [‘a_Wifi_Availibility’,’a_Couple_Friendly’,’a_Budget_Friendly’,’a_Nature_Friendly’,’a_Star_Rating’]
header_hotel_features = [‘Wifi_Availibility’,’Couple_Friendly’,’Budget_Friendly’,’Nature_Friendly’,’Star_Rating’]
assembler_features = VectorAssembler(inputCols= header_user_aban, outputCol=”user_features”)
assembler_features_2 = VectorAssembler(inputCols= header_hotel_features, outputCol=”hotel_features”)
tmp = [ assembler_features,assembler_features_2]
pipeline = Pipeline(stages=tmp)
baseData = pipeline.fit(abandoned_dataset).transform(abandoned_dataset)
df_final = baseData
def cos_sim(value,vec):
if (np.linalg.norm(value) * np.linalg.norm(vec)) !=0:
dot_value = np.dot(value, vec) / (np.linalg.norm(value)*np.linalg.norm(vec))
return dot_value.tolist()
cos_sim_udf = udf(cos_sim, FloatType())
abandon_final = df_final.withColumn(‘cosine_dis’, cos_sim_udf(‘user_features’,’hotel_features’))
abandon_final.withColumn(‘recommendation_rank’,F.row_number().over(Window.partitionBy(‘User_ID’).orderBy(desc(‘cosine_dis’)))).show()
Code for historical users:
historical_dataset = historical_users_info.join(hotel_type,[‘location_ID’],’left’)
header_user_hist = [‘wifi_flag’,’couple_flag’,’budget_flag’,’nature_flag’,’avg_star_rating’]
header_hotel_features = [‘Wifi_Availibility’,’Couple_Friendly’,’Budget_Friendly’,’Nature_Friendly’,’Star_Rating’]
assembler_features = VectorAssembler(inputCols= header_user_hist, outputCol=”user_features”)
assembler_features_2 = VectorAssembler(inputCols= header_hotel_features, outputCol=”hotel_features”)
tmp = [ assembler_features,assembler_features_2]
pipeline = Pipeline(stages=tmp)
baseData = pipeline.fit(historical_dataset).transform(historical_dataset)
df_final = baseData
def cos_sim(value,vec):
if (np.linalg.norm(value) * np.linalg.norm(vec)) !=0:
dot_value = np.dot(value, vec) / (np.linalg.norm(value)*np.linalg.norm(vec))
return dot_value.tolist()
cos_sim_udf = udf(cos_sim, FloatType())
historical_final = df_final.withColumn(‘cosine_dis’, cos_sim_udf(‘user_features’,’hotel_features’))
historical_final.withColumn(‘recommendation_rank’,F.row_number().over(Window.partitionBy(‘User_ID’).orderBy(desc(‘cosine_dis’)))).show()
Our output will look like the following:

historical users

abandoned users
Giving Recommendations:
Giving 3 recommendations per user, our final output will look like the following:
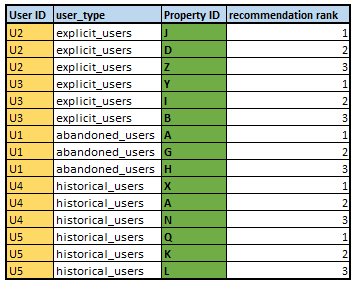
Note:
One can notice that we are not using hotel recommendation X for the abandoned user U1 as a first recommendation we are avoiding so as hotel features were created from the same property ID, hence, it will always be at rank 1
Unlike cosine similarity where 0’s are considered a negative preference, Pearson correlation does not penalize the user if no input is given; hence we use the latter for explicit users
Conclusion:
In the end, the objective is to fully understand the problem statement, work around the data available, and provide recommendations with a nascent system.