Human Activity Recognition: Fusing Modalities for Better Classification

Human Activity Recognition using high-dimensional visual streams has been gaining popularity in recent times. Using a video input to categorize human activity is primarily applied in surveillance of different kinds. At hospitals and nursing homes, this can be used to immediately alert caretakers when any of the residents are displaying any sign of sickness – clutching their chest, falling, vomiting, etc. At public places like airports, railway stations, bus stations, malls or even in your neighborhoods, the activity recognition becomes the means to alert authorities on recognizing suspicious behavior. This AI solution is even useful for identifying flaws in and improving the form of athletes and professionals ensuring improved performance and better training.
Why Use Multimodal Learning for Activity Recognition?
Our experience of the world is multimodal in nature, as quoted by Baltrušaitis et al. There are multiple modalities a human is blessed with. We can touch, see, smell, hear, and taste, and understand the world around us in a better way. Most parents would remember their kid’s understanding of “what a dog is” keeps improving after seeing actual dogs, videos of dogs, photographs of dogs and cartoon dogs and being told that they are all dogs. Just seeing a single video of an actual dog does not help the kid identify the character “Goofy” as a dog. It is the same for machines. Multimodal machine learning models can process and relate the information from multiple modalities, learning in a more holistic way.
This blog serves as the captain’s log on how we combined the effectiveness of two modalities – Static Images and Videos – to improve the classification of human activities from videos. Algorithms for video activity recognition are based on dealing with only spatial information (images), or both spatial and temporal information (videos). Algorithms were used for both static images and videos for the activity recognition modeling. Fusing both models together made the resultant multimodal model far better than each of the individual unimodal models.
Multimodal Learning for Human Activity Recognition – Our Recipe
Our goal was to recognize 10 activities – basketball, biking, diving, golf swing, horse riding, soccer juggling, tennis swing, trampoline jumping, volleyball spiking, and walking. We created the multimodal models for activity recognition by fusing the two unimodal models – image-based and video-based – using the ensemble method, thus enhancing the effect of the classifier.
The Dataset Used: We have used modified UCF11 dataset (removed Swing class as it has many mis-labelled data). For the 10 activities we need to classify, the dataset has 120-200 videos of different lengths ranging from 1-21 seconds. The link to the dataset is (CRCV | Center for Research in Computer Vision at the University of Central Florida (ucf.edu)).
One Modality at a Time
There are different methodologies for Multimodal learning as is described by Song et al., 2016, Tzirakis et al., 2017, and Yoon et al., 2018. One of the techniques is ensemble learning, in which 2DCNN model and 3DCNN models are trained separately and the final softmax probabilities are combined to get predictions. Other techniques include joint representation, coordinated representation etc. A detailed overview is available in Baltrušaitis et al., 2018.
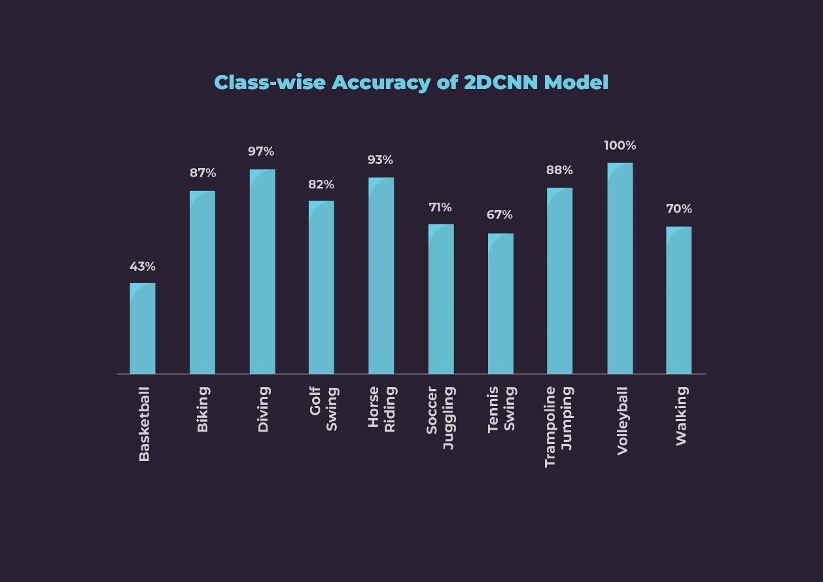
The First Modality – Images: We trained a 2DCNN model with VGG-16 architecture and equipped our model with batch normalization and other regularization methods, since the enormous number of frames
caused overfitting. We observed that deeper architectures were less accurate. We achieved 81% clip-wise accuracy. However, the accuracies are very poor on some classes such as basketball, soccer juggling, tennis, and walking as can be seen below.
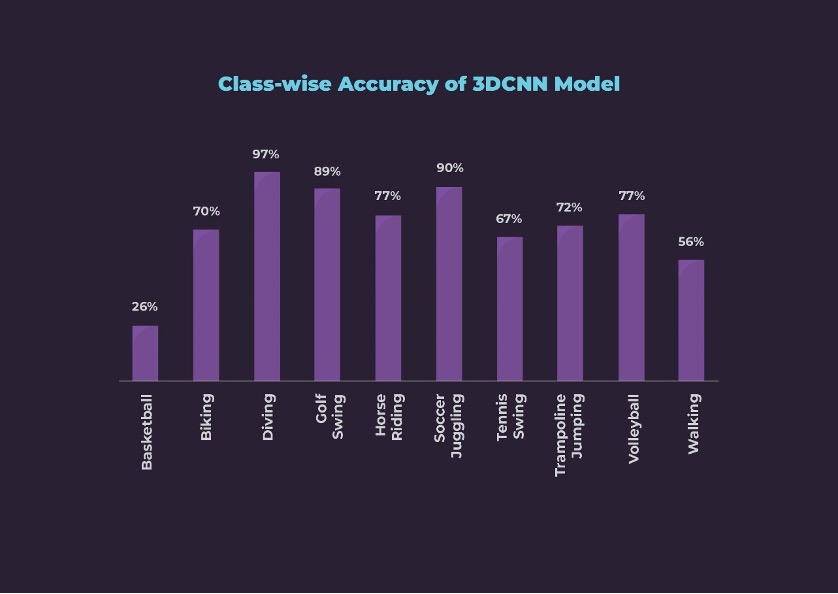
Second Modality – Videos: The second model was trained with 3DCNN architecture, which took 16 frames as one chunk called as a block. We incorporated various augmentations, batch normalization, and regularization methods. During the exercise, we observed that 3D architecture is sensitive to the learning rate. In the end, we achieved a clip-wise accuracy of 73%. Looking at the accuracies for individual classes, this model is not the best, but it is much better than the 2DCNN for Soccer Juggling and Golf classes. Class-wise accuracies can be seen below.
Our next objective was to ensure that the learnings from both modalities are combined to create a more accurate and robust model.
Our Secret Sauce for Multimodal learning – The Ensemble Method
For fusing the two modalities, we resorted to ensemble methods (Zhao, 2019). We experimented with two ensemble methods for the Multimodal learning:
1. Maximum Vote – Mode from the predictions of both models is taken as the predicted label.
2. Averaging and Maximum Pooling – Weighted sum of probabilities of both models is calculated to decide the predicted label.
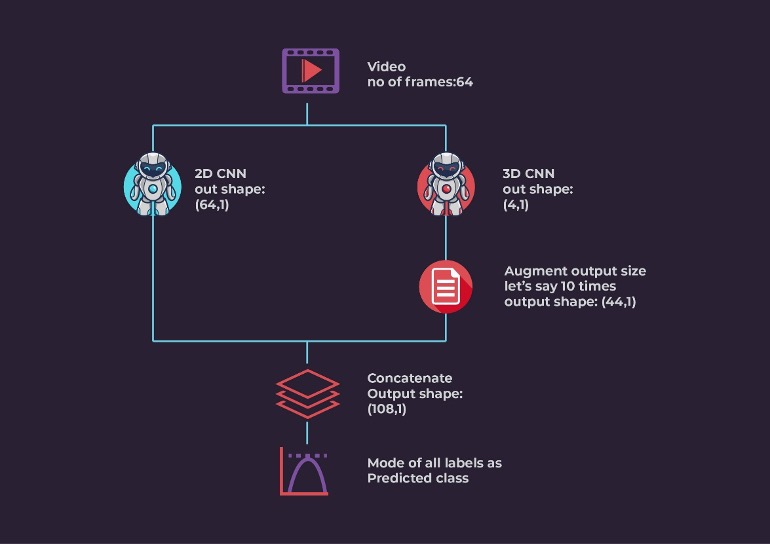
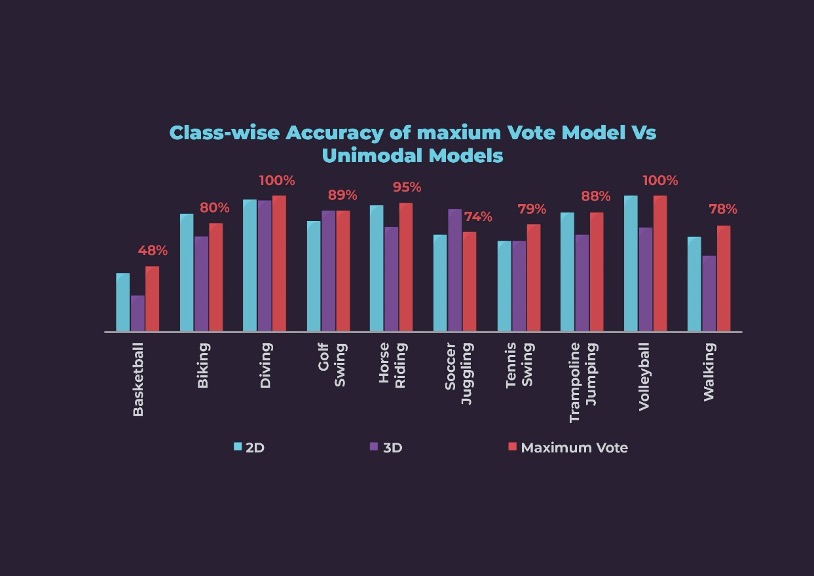
Maximum Vote Ensemble Approach: Let us consider a video consisting of 64 frames. We fed these frames to both 2D and 3D models. The 2D model produced an output for each frame resulting in 64 tensors with a predicted label. Similarly, the 3D model produced a label for 16 frames, thus finally generating 4 tensors for 64 frames video. To balance the weightage of the 3D model, we augment the output tensors of the 3D model by repeating the tensor multiple times. Finally, we concatenated the output tensors from both models, and selected the modal class (the class label with the highest occurrence) as the prediction label.
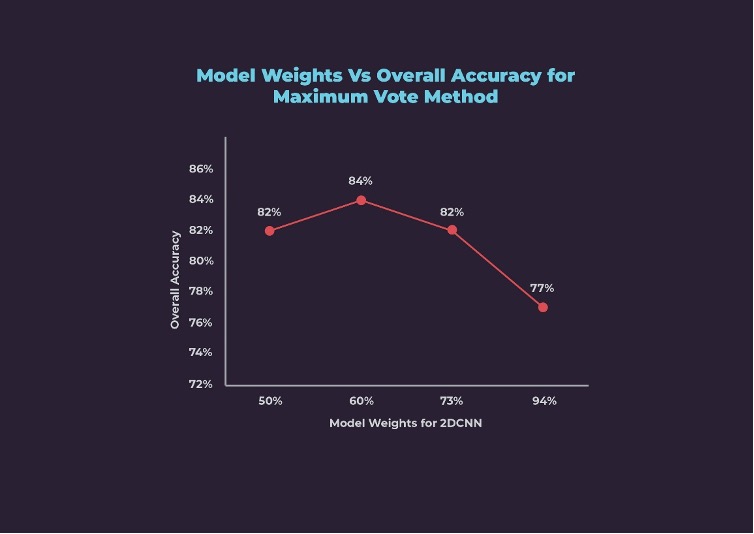
We iteratively experimented with different weightages for both models and checked the corresponding overall accuracy as shown below. Maximum overall accuracy of 84% was achieved at 60% weightage to the 2D model and 40% weightage to the 3D model.
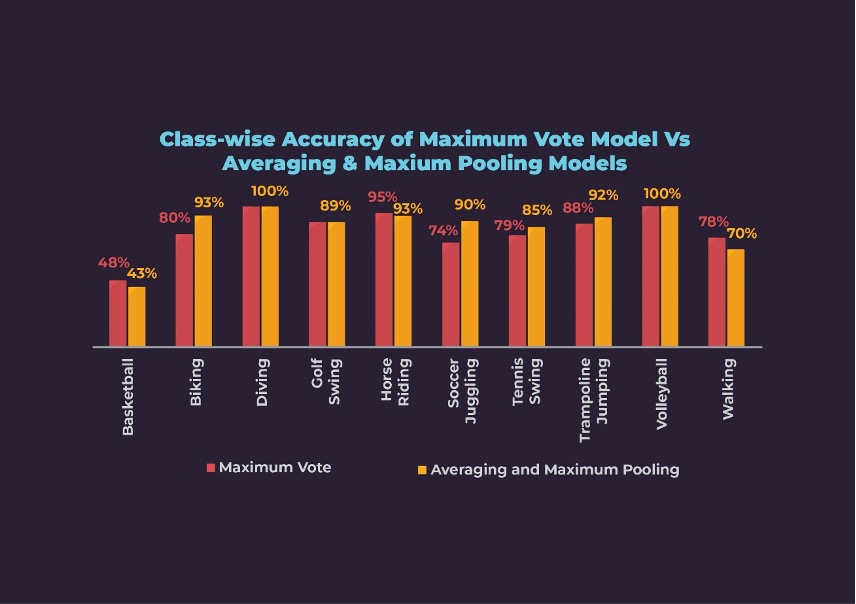
At 60:40 weightage for 2D:3D, the Maximum Vote ensemble method has performed better than either of the unimodal models except for Biking and Soccer Juggling.
Averaging and Maximum Pooling Ensemble Method: Consider that we are feeding a video with 64 frames to both models, the 2D model which generates 64 tensors with probabilities for every class and the 3D model will generate 4 tensors with probabilities for each of 10 classes. We calculate the average of all 64 tensors from the 2D model to get the average probability for every class. Similarly, we calculate the average of the 4 tensors from the 3D model. Finally, we take the weighted sum of resulting tensors from both models. We select the class with maximum probability as the predicted class.
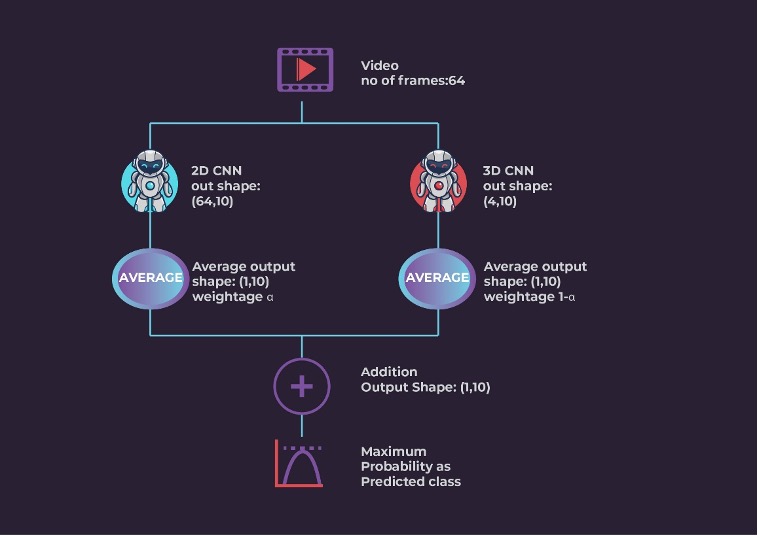
The equation for the weight in Averaging and Maximum Pooling method is:
Multimodal = α*(2D Model) + (1-α)*(3D Model)
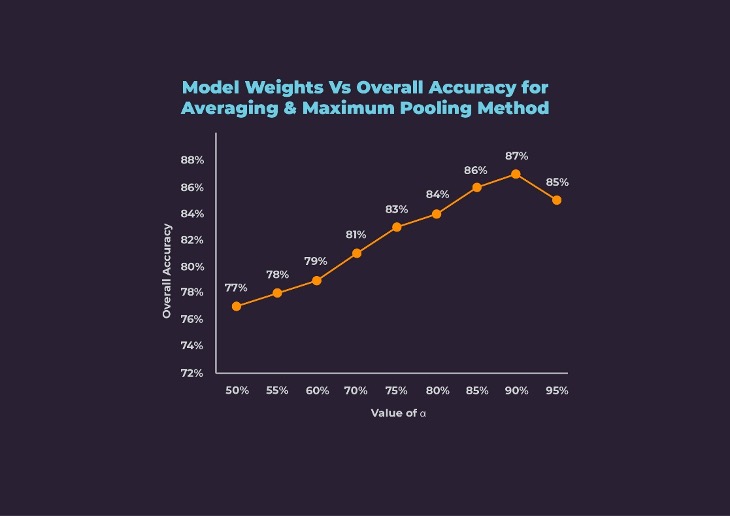
We experimented with different values of α and compared the resulting overall accuracies as shown below. With equal weightage to both models, we achieved 77% accuracy. With the increase in α, i.e., weightage to 2D model, multimodal accuracy increased. We achieved the best accuracy of 87% at 90% weightage to the 2D model and 10% weightage of the 3D model.
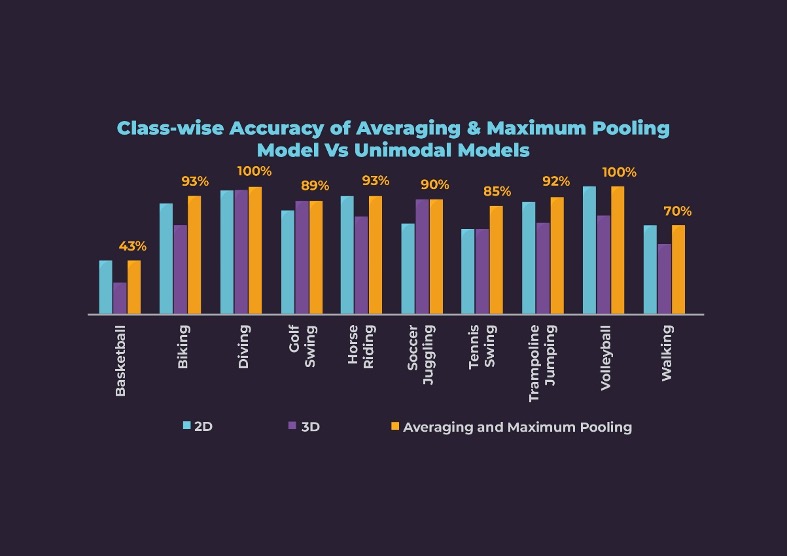
The class-wise accuracy for the Averaging and Maximum Pooling method is low for Basketball and Walking classes. However, the class-wise accuracies are better than or at least the same as the unimodal models. The accuracies for Soccer Juggling and Tennis Swing improved the most from 71% and 67% for the 2D model to 90% and 85% respectively.
Conclusion
Beyond doubt, our Multimodal models performed better than the Unimodal ones. Comparing the multimodal engines, Averaging and Maximum Pooling performed better than the Maximum Vote method, as is evident from the overall accuracies of 87% and 84% respectively. The reason is that the Averaging and Maximum Pooling method considers the confidence of the predicted label whereas, the Maximum Vote method considers only the label with maximum probability.
In Human Activity Recognition, we believe the multimodal learning approach can be improved further by incorporating other modalities as well. Such as Facebook’s Detectron model or pose estimation method.
Our next plan of action is to explore more forms of multimodal learning for activity recognition. Using features addition/ layers are fusing features can be effective in learning features better. Another way of proceeding would be to add different modalities like pose detection feed, motion detection feed and object detection feed to provide better results. No matter the approach, fusing modalities has a corresponding cost factor associated with it. While we have 40.4 million trainable parameters in the 2DCNN model and 78 million parameters in the 3DCNN models, the multimodal model has 118.5 million parameters to train on. But this is a small amount to pay considering the limitless applications that can be made viable because of the performance improvement provided by the multimodal models.