Super-Resolution with Deep Learning for Image Enhancement

Have you ever looked at your old photographs and hoped it had better quality? Or wished to convert all your photos to a better resolution to get more likes? Well, Deep learning can do it!
Image Super Resolution can be defined as increasing the size of small images while keeping the drop-in quality to a minimum or restoring High Resolution (HR) images from rich details obtained from Low Resolution (LR) images.
The process of enhancing an image is quite complicated due to the multiple issues within a given low-resolution image. An image may have a “lower resolution” as it is smaller in size or as a result of degradation. Super Resolution has numerous applications like:
- Satellite Image Analysis
- Aerial Image Analysis
- Medical Image Processing
- Compressed Image
- Video Enhancement, etc.
We can relate the HR and LR images through the following equation:
LR = degradation(HR)
The goal of super resolution is to recover a high-resolution image from a low-resolution input.
Deep learning can estimate the High Resolution of an image given a Low Resolution copy. Using the HR image as a target (or ground-truth) and the LR image as an input, we can treat this like a supervised learning problem.
One of the most used techniques for upscaling an image is interpolation. Although simple to implement, this method faces several issues in terms of visual quality, as the details (e.g., sharp edges) are often not preserved.
Most common interpolation methods produce blurry images. Several types of Interpolation techniques used are :
- Nearest Neighbor Interpolation
- Bilinear Interpolation
- Bicubic Interpolation
Image processing for resampling often uses Bicubic Interpolation over Bilinear or Nearest Neighbor Interpolation when speed is not an issue. In contrast to Bilinear Interpolation, which only takes 4 pixels (2×2) into account, bicubic interpolation considers 16 pixels (4×4).
SRCNN was the first Deep Learning method to outperform traditional ones. It is a convolutional neural network consisting of only three convolutional layers:
- Pre-Processing and Feature Extraction
- Non-Linear Mapping
- Reconstruction
Before being fed into the network, an image needs up-sampling via Bicubic Interpolation. It is then converted to YCbCr (Y Component and Blue-difference to Red-difference Chroma Component) color space, while the network uses only the luminance channel (Y). The network’s output is then merged with interpolated CbCr channels to produce a final color image. This procedure intends is to change the brightness (the Y channel) of the image while there is no change in the color (CbCr channels) of the image.
The SRCNN consists of the following operations:
- Pre-Processing: Up-scales LR image to desired HR size.
- Feature Extraction: Extracts a set of feature maps from the up-scaled LR image.
- Non-Linear Mapping: Maps the feature maps representing LR to HR patches.
- Reconstruction: Produces the HR image from HR patches.
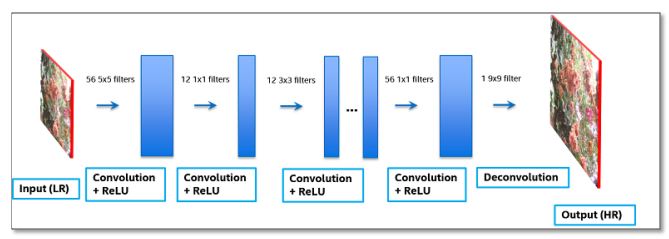
LR images are preserved in SR image to contain most of the information as a super-resolution requirement. Super-resolution models, therefore, mainly learn the residuals between LR and HR images. Residual network designs are, therefore, essential.
Up-Sampling Layer¶
The up-sampling layer used is a sub-pixel convolution layer. Given an input of size H×W×CH×W×C and an up-sampling factor ss, the sub-pixel convolution layer first creates a representation of size H×W×s2CH×W×s2C via a convolution operation and then reshapes it to sH×sW×CsH×sW×C, completing the up-sampling operation. The result is an output spatially scaled by factor ss
Enhanced Deep Residual Networks (EDSR)
Furthermore, when super resolution techniques started gaining momentum, EDSR was developed which is an enhancement over the shortcomings of SRCNN and produces much more refined results.
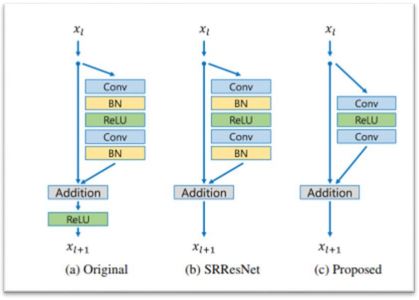
EDSR network consists of :
- 32 residual blocks with 256 channels
- pixel-wise L1 loss instead of L2
- no batch normalization layers to maintain range flexibility
- scaling factor of 0.1 for residual addition to stabilize training
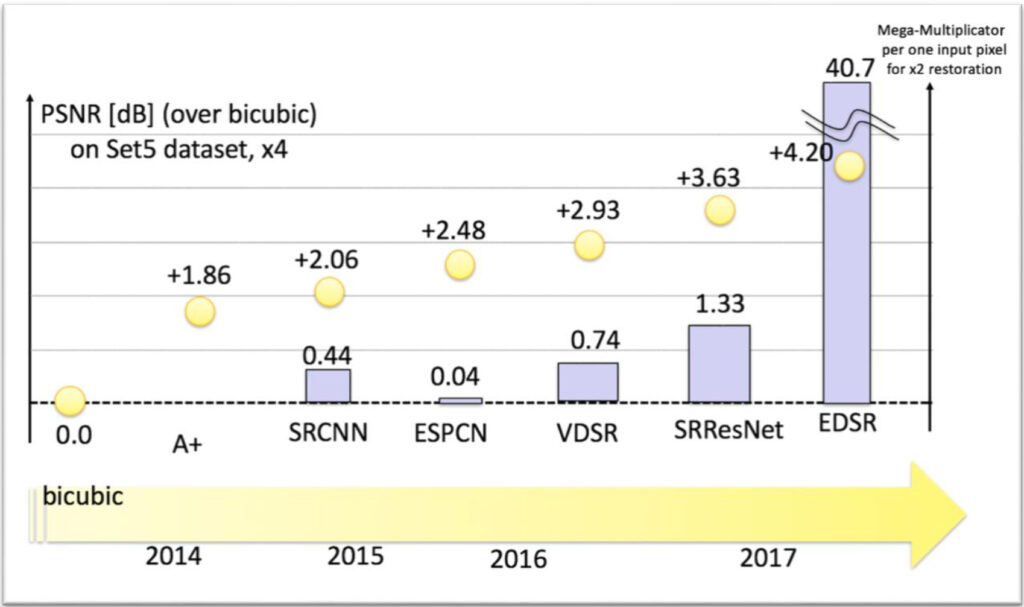
On comparing several techniques, we can clearly see a trade-off between performance and speed. ESPCN looks the most efficient while EDSR is the most accurate and expensive. You may choose the most suitable method depending on the application.
Further, I have implemented Super Resolution using EDSR on few images as shown below:
- Importing Modules

This block of code imports all the necessary modules needed for training. DIV2K is the dataset that consists of Diverse 2K resolution-high-quality-images used in various image processing codes. EDSR algorithm is also imported here for further training.
- Defining the Parameters

This block of code assigns the number of residual blocks as 16. Furthermore, the super resolution factor and the downgrade operator is defined. Higher the number of residual blocks, better the model will be in capturing minute features, even though its more complicated to train the same. And hence, we stick with residual blocks as 16.

A directory is created where the model weights will be stored while training

Images are downloaded from DIV2K with two folders of train and a valid consisting of both low and high resolution.
Once, the dataset has been loaded, both the train and valid images need to be converted into TensorFlow dataset objects.
- Training the Model
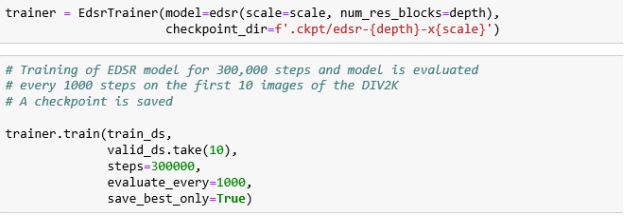
Now the model is trained with the number of steps as 30k. The image is evaluated using the generator every 1000th step. The training takes around 12 hours in Google Colab GPU.

- Obtaining the Result
Furthermore, the models are saved and can be used in the future for further modifications.
For output, the model is loaded using weight files and further both the images of low resolution and high resolution are plotted simultaneously for comparison.
High-Resolution Images showcased on the right are obtained by applying the Super-Resolution algorithm on the Low-Resolution Images showcased on the left.




Conclusion
You can clearly observe a significant improvement in the resolution of images post-application of the Super-Resolution algorithm, making it exceptionally useful for Spacecraft Images, Aerial Images, and Medical Procedures that require highly accurate results.