Recommendation Systems for Marketing Analytics

How I perceive recommendation systems is something which the traditional shopkeepers used to use.
Remember the time when we used to go shopping with our mother in the childhood to the specific shop. The shopkeeper used to give the best recommendations for the products, and we used to buy it from the same shop because we knew that this shopkeeper knows us best.
What the shopkeeper did was he understood our taste, priorities, the price range that we are comfortable with and then present the products which best matched our requirement. This is what the businesses are doing in the true sense now.
They want to know their customer personally by their browsing behaviour and then make them recommendation of the products that they might like, the only thing is that they want to do it on a large scale.
For example, Amazon and Netflix understand your behaviour through what you browse, add to basket and order, movies you watch and like and then recommend the best of the products which you make like with high probability.
In a nutshell, they combine what you call as the business understanding with some mathematics so that we can essentially know and learn about the products that the customer likes.
So basically, as recommendation system for marketing analytics is a subclass of information filtering system that seeks the similarities between users and items with different combinations.
Below are some of the most widely used types of recommendation systems:
- Collaborative Recommendation system
- Content-based Recommendation system
- Demographic based Recommendation system
- Utility based Recommendation system
- Knowledge based Recommendation system
- Hybrid Recommendation system
Let us go into the most useful ones which the industry is using:
- Content Based Recommendation System
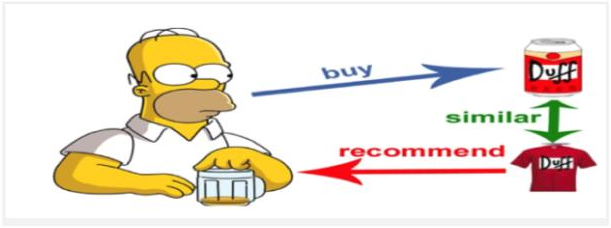
The point of content-based is that we should know the content of both user and item. Usually we construct user-profile and item-profile using the content of shared attribute space. The product attributes like image (Size, dimension, colour etc…) and text description about the product is more inclined towards “Content Based Recommendation”.
This essentially means that based upon the content that I watch on Netflix, I can run an algorithm to see what the most similar movies are and then recommend the same to the other users.
For example, when you open Amazon and search for a product, you get the similar products pop up below which is the item-item similarity that they have computed for the overall products that are there in Amazon. This gives us a very simple yet effective idea of how the products behave with each other.
Bread and butter could be similar products in the true sense as they go together but their attributes can be varied. In case of the movie industry, features like genres, reviews could tell us the
similar movies and that is the type of similarity we get for the movies.
- Collaborative Recommendation System:
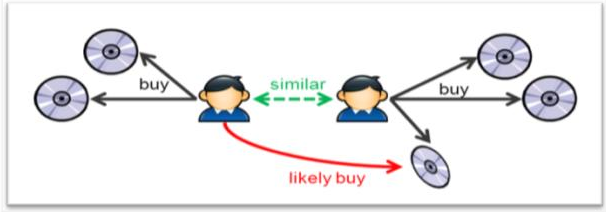
Collaborative algorithm uses “User Behaviour” for recommending items. They exploit behaviour of other users and items in terms of transaction history, ratings, selection, purchase information etc. In this case, features of the items are not known.
When you do not want to see what the features of the products are for calculating the similarity score and check the interactions of the products with the users, you call it as a collaborative approach.
We figure out from the interactions of the products with the users what are the similar products and then take a recommendation strategy to target the audience.
Two users who watched the same movie on Netflix can be called similar and when the first user watches another movie, the second users gets that same recommendation based on the likes that these people have.
- Hybrid Recommendation System:
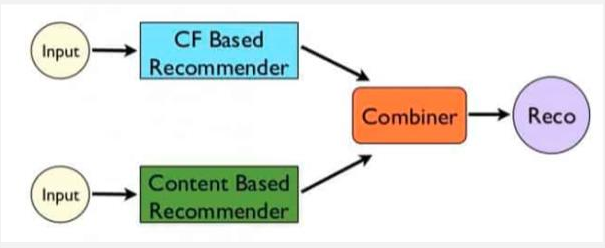
Combining any of the two systems in a manner that suits the industry is known as Hybrid Recommendation system. It combines the strengths of more than two Recommendation system and eliminates any weakness which exist when only one recommendation system is used.
When we only use Collaborative Filtering, we have a problem called as “cold start” problem. As we take into account the interaction of users with the products, if a user comes to the website for the first time, I do not have any recommendations to make to that customer as I do not have interactions available.
To eliminate such a problem, we used hybrid recommendation systems which combines the content-based systems and
collaborative based systems to get rid of the cold start problem. Think of it as this way, item-item and user-user, user-item interaction all combined to give the best recommendations to the users and to give more value to the business.
From here, we will focus on the Hybrid Recommendation Systems and introduce you to a very strong Python library called lightfm which makes this implementation very easy.
LightFM:
The official documentation can be found in the below link:
lyst/lightfm
Build status Linux OSX (OpenMP disabled) Windows (OpenMP disabled) LightFM is a Python implementation of a number of…
github.com
LightFM is a Python implementation of the number of popular recommendation algorithms for both implicit and explicit feedback.
User and item latent representations are expressed in terms of their feature’s representations.
It also makes it possible to incorporate both item and user metadata into the traditional matrix factorization algorithms. When multiplied together, these representations produce scores for every item for a given user; items scored highly are more likely to be interesting to the user.
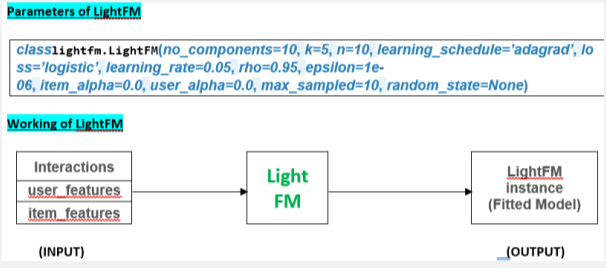
Interactions : The matrix containing user-item interactions.
User_features : Each row contains that user’s weights over features.
Item_features : Each row contains that item’s weights over features.
Note : The matrix should be Sparsed (Sparse matrix is a matrix which contains very few non-zero elements.)
Predictions
fit_partial : Fit the model. Unlike fit, repeated calls to this method will cause training to resume from the current model state.
Works mainly for the new users to append to the train matrix.
Predict : Compute the recommendation score for user-item pairs.
The scores are sorted in the descending form and top n-items are recommended.
Model evaluation
AUC Score : In the binary case (clicked/not clicked), the AUC score has a nice interpretation: it expresses the probability that a randomly chosen positive item (an item the user clicked) will be ranked higher than a
randomly chosen negative item (an item the user did not click). Thus, an AUC of 1.0 means that the resulting ranking is perfect: no negative item is ranked higher than any positive item.
Precision@K : Precision@K measures the proportion of positive items among the K highest-ranked items. As such, this is focused on the ranking quality at the top of the list: it does not matter how good or bad the rest of your ranking is as long as the first K items are mostly positive.
Ex: Only one item of your top 5 item are correct, then your precision@5 is 0.2
Note : If the first K recommended items are not available anymore (say, they are out of stock), and you need to move further down the ranking. A high AUC score will then give you confidence that your ranking is of high quality throughout.
Enough of the theory now, we will move to the code and see how the implementation for lightfm works:
I have taken the dataset from Kaggle, you can download it below:
E-Commerce Data
Actual transactions from UK retailer www.kaggle.com
Hope you liked the coding part of it, and you are ready to implement that in any version. The enhancement that can be done in this is if you have the product and the user features.
These can also be taken as inputs into the lightfm model and the embedding that the model creates would be based upon all those attributes. The more data that is pushed into the lightfm will give the model a better accuracy and more training data.
That’s all from my end for now. Keep Learning!! Keep Rocking!!