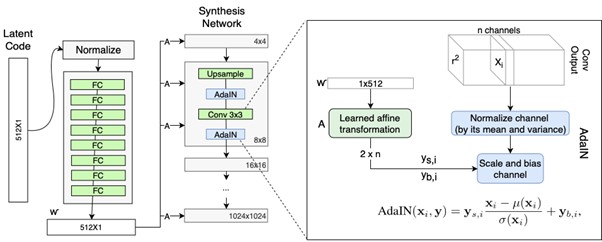
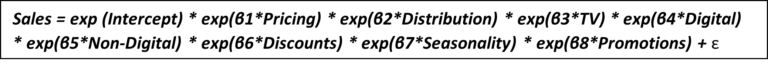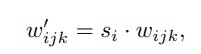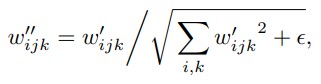“Cinema is a mirror by which we often see ourselves.” – Alejandro Gonzalez Inarritu
If 500 people saw a movie, there exist 500 different versions of the same idea conveyed by the movie. Often movies reflect culture, either what the society is or what it aspires to be.

From “Gone with the Wind” to “Titanic” to “Avengers: Endgame,” Movies have come a long way. The Technology, Scale, and Medium might have changed, but the essence has remained invariable to storytelling. Any idea or story that the mind can conceive can be given life in the form of Movies.
The next few minutes would be a humble attempt to share the What, Why, and How of the Movie Industry.
Sections:
- The process behind movies
- How did the movie industry operate?
- How is it functioning now?
- What will be the future for movies?
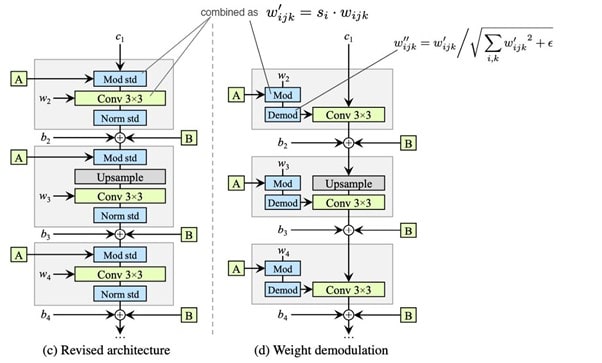
1. The process behind movies
We see the end output in theatres or in the comfort of our homes (on Over-The-Top (OTT) platforms like Netflix, Amazon Prime, HBO Max, etc.). But in reality, there is a long and ardent process behind movie-making.
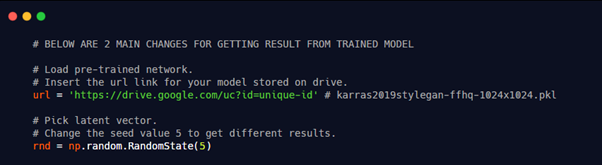
As with all things, it starts with an idea, an idea that transcribes into a story, which then takes the form of a script detailing the filmmaker’s vision scene by scene.
They then pitch this script to multiple studios (Disney, Universal, Warner Bros., etc.). When a studio likes this script, they decide to make the film using its muscle for pre-production, production, and post-production.
The filmmaker and studio start with the pre-production activities such as hiring cast and crew, choosing filming locations to set constructions. Post which the movie goes into the production phase, where it gets filmed. In post-production, the movie gets sculpted with music, visual effects, video & sound editing, etc.
And while moviemakers often understand the art of movie-making, it becomes a product to be sold on completing production. Now they have to sell this story to the audience.
Marketing & distribution step in to ensure that this product is now available to its worldwide audience by promoting it in all possible mediums like billboards and social media. After this, it’s all about delivering an immersive, entertaining experience where your surroundings go dark and the mind lights up.
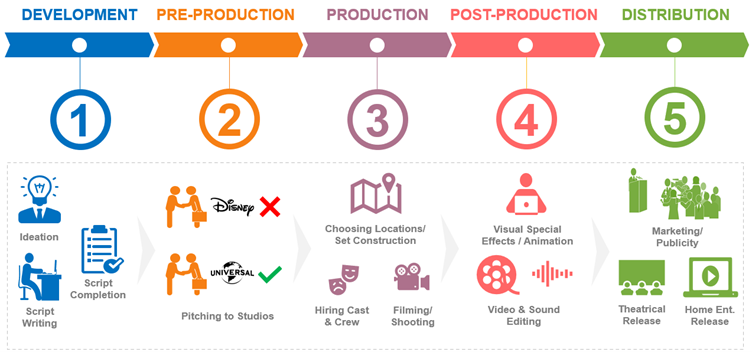
An Overview Of The Movie-Making Process
In recent times some creative flexibility has been observed in the above process. For example, studios who own certain characters or intellectual property like Marvel & DC characters hire the right talent to get their movies made. In such cases, big studios control significant aspects of the film, from content creation to distribution.
2. How did the movie industry operate?
For a considerable period, movies used to stay in theatres for a long time post their initial release before reaching other available forms of Home Entertainment (based on the technological choices/era). For example, Let’s take a movie that acted as the bridge between two distinct generations. Titanic transformed the industry from the old school blockbusters to the new school global hits (with technology, CGI, worldwide markets, etc.) And before the 2010s, blockbuster movies like Titanic used to run in theatres for several months. Titanic was the undisputed leader of Box Office for nearly four months, both in terms of the number of tickets sold and worldwide revenue generated.
Post its theatrical run of approximately four months, blockbuster titles used to be available in-Home Entertainment (HE) formats (such as DVD, VCD, etc.) These formats were available in various options based on the decade or era. Options such as rental or purchasable DVDs ruled the HE domain for a considerable amount of time. Until the emergence of the internet.
The Dawn of the internet brought in other sources of entertainment in competition to the traditional Movies, Sports, etc. These options gave the consumer alternate forms of entertainment (which resulted in shortened theatrical runs, approximately three months or less). They gave the studios also another platform to sell their content. Hence the Home Entertainment release windows were fast-tracked as a natural consequence to capitalize the most from the movie’s potential.
The following is an example of the pre-2020/pandemic norms in Hollywood.
- December 25: Movie releases in Theatres (TH). Ex: Fast and Furious March 10 19: EST (Electronic Sell Through) release of the movie (Ex: Amazon, iTunes)
- April 2: iVOD/cVOD (Internet/Cable Video on Demand) release of the movie (Ex: YouTube, Comcast, Amazon)
- April 30: PST (Physical Sell Through) release of the movie (Ex: DVDs, Blu-ray discs)
- After this, the movie becomes available on Linear TV networks (Ex: HBO)
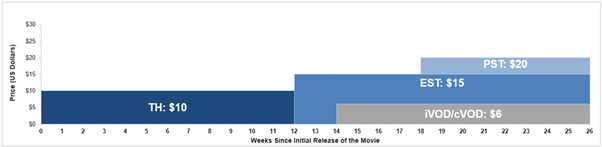
An Overview Of Movie Releases Before And After Pandemic
3. How is it functioning now?
Amid all the uncertainty surrounding the COVID pandemic, the movie industry did come to a halt, as did many other integral aspects of people’s lives. Around March 2020, most theatres worldwide shut down to prevent the widespread pandemic. The forceful shutting of the movie industry immobilized crucial aspects of the filmmaking process, such as the filming & theatrical release of movies. Since it was not safe for people to gather in numbers, theatres closed, as did other forms of entertainment such as Concerts, Live Sports, etc. This change of unprecedented magnitude was the first since world wars, where major entertainment activities worldwide were shut down.
With every problem, there lies an opportunity, as with this change, innovation was the name of the game. Those businesses that innovated survived, and the rest were likely to perish. The founding stone for this innovation was laid a long time back. With the influx of the internet, OTT (Over-The-Top) & VOD (Video on Demand) platforms were rapidly growing. OTT Platforms like Netflix & Amazon Prime were significant players in the US and worldwide before the beginning of the pandemic itself.
Shutting down of theatres meant some movies slated for 2020 waited for release dates. In the movie industry, movies are often planned well in advance. Major studios are likely to have tentative release dates for the upcoming 2 to 3 years. Delaying movies of the current year not only does it cumulatively delay the subsequent year’s release dates, but it also decays the potential of the film (due to factors like heavy competition later, loss of audience interest, etc.)
Major studios & industry leaders lead the way with innovation. A new format (Premium Video on Demand) and a new release strategy were the most viable options to ensure the movie’s release, guaranteeing both financial and viewership success.
The New Format – PVOD (Premium Video on Demand) was essentially releasing the iVOD/cVOD rental formats at an earlier period by shortening the pre-pandemic normal of 12 weeks post-theatrical release window to an earlier release window.
There were two ways of doing this; the first one is a Day and Date release in PVOD, which meant the audience can watch a new movie (Ex: Trolls World Tour, Scoob!) on its first release date at the comfort of their homes via the PVOD/rental channels (Ex: Amazon/iTunes)
The second way for the PVOD format is by releasing the movie in PVOD 2 to 8 weeks post its release in theatres. This happened once people got used to the new normal during the pandemic. Theatres across the world opened partially with limited seating capacity (50%). This meant that a movie would release in theatres exclusively first (as it was previously). However, the traditional Home Entertainment window of 12 weeks bypassed to release PVOD at an early window of 2 to 8 weeks post Theatrical release. This was the key in catering to a cautious audience during the pandemic between 2020 to 2021. This enabled them to watch a newly released movie at the comfort of their homes within a couple of weeks of its initial release itself.
A similar strategy was also tried with EST, where an early EST release (Premium EST or PEST) is offered to people at an early release window. The key difference is that PEST and PVOD were sold at higher price points (25% higher than EST/iVOD/cVOD) due to their exclusivity and early access.
The other strategy was a path-breaking option that opened the movie industry to numerous viable release possibilities – a direct OTT release. A movie waiting for its release & does not want to use the PVOD route due to profitability issues, or other reasons can now release the film directly on OTT platforms like Netflix & Amazon Prime. These platforms, which were previously producing small to medium-scale series & movies, now have the chance to release potential blockbuster movies on their platform. Studios also get to reach Millions of customers across the globe at the same time by jumping certain cumbersome aspects posed by the conventional theatrical distribution networks (which includes profit-sharing mechanisms). In this route of OTT platform release, there are many advantages to all parties involved (Studios, OTT Platforms & Audiences) and the number of potential customers.
The studios either get a total remuneration paid for the movie upfront (e.g., Netflix made a $200 Million offer for Godzilla vs. Kong to its producers, Legendary Entertainment & Warner Bros.). Or get paid later based on the number of views gathered in a given period or a combination of both (depending upon the scale & genre of the movie). The OTT platforms will now have a wide array of the latest movies across all genres to attract & retain customers. The people will now get to watch new movies on their preferred OTT platforms at their convenience and get a great value for money spent (OTT 1-month subscription ~$10 for new movie + existing array of movies & series vs. ~ $10 Theatre Ticket Price for one movie)
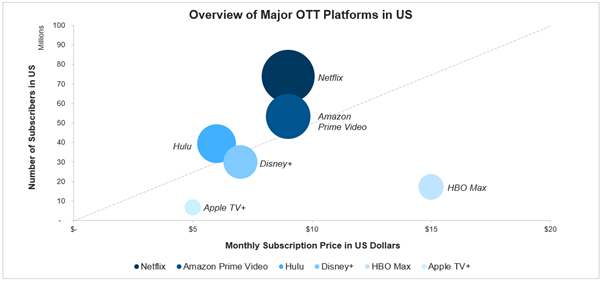
Overview of Major OTT Platform in US
Given there are two new gateways (OTT & PVOD) to release films in addition to the existing conventional mediums such as Theatres, EST, iVOD, cVOD, PST. There are numerous beneficial ways a movie can be released to reach the maximum people & make the most profit for the filmmakers & studios.
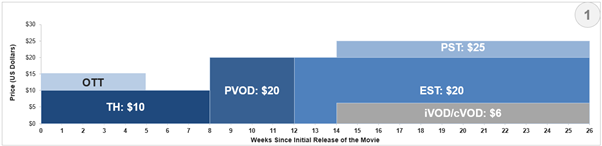
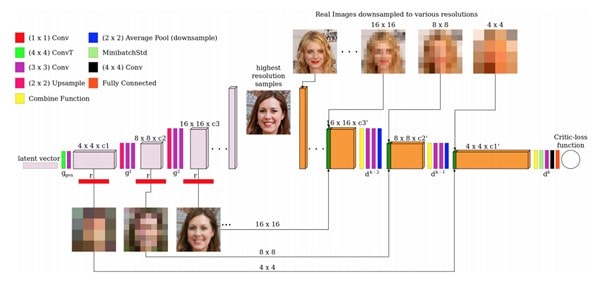
Release Strategy Examples
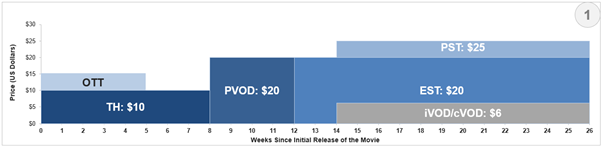
In the above example, releasing a movie directly in OTT in parallel to theatrical release attracts more subscribers to the OTT platform and covers the traditional theatrical audiences.
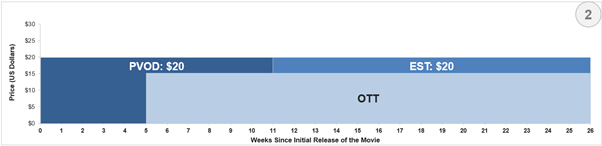
In the second example, let’s take a direct to Home Entertainment approach, targeting audiences directly in PVOD & early OTT releases. Similar to the movies that were released during the pandemic, like Trolls World Tour & Scoob!
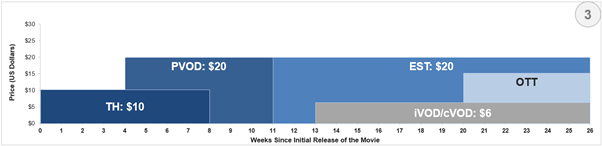
The third example shows a possibility where a movie can leverage all existing major platforms for a timely release.
Since there are hundreds of possibilities for any studio or filmmaker to release their movies, how would one know the best release strategy for a movie? Does one size fit all methods work? Or do we scale and change release strategies according to the Budget/Content of the movie? Are certain genre films more suited for large-scale theater experience than being better suited for Home Entertainment? Who decides this? That should be a straightforward answer. In most cases, the one who finances the film decides the release strategy. But how would they know what combination ensures the maximum success to recoup the amount invested and guarantee a profit for all involved?
In such an uncertain industry, where more movies fail than succeed (considering the bare minimum of breaking even), the pandemic-induced multiple release strategies compound the existing layers of complexity.
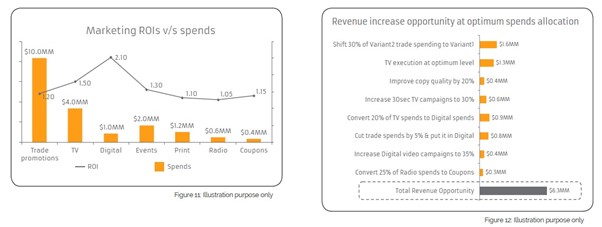
In an ocean of uncertainties, the ship with a compass is likely to reach the shore safely. The compass, in this case, is Analytics. Analytics, Insights & Strategy provide the direction to take the movie across to the shores safely and profitably.
Analytics, Insights & Strategy (AIS) helps deal with the complex nature of movies and provides a headstrong direction for decision making, be it from optimal marketing spend recommendations to profitable release strategies. There are thousands of films with numerous data points. When complex machine learning models leverage all this data, it yields eye-opening insights for the industry leaders to make smart decisions. Capitalizing on such forces eases the difficulties in creating an enjoyable & profitable movie.
4. What will be the future for movies?
The Entertainment industry evolves as society progresses forward. Movies & theatres have stood the test of time for decades. There will always be a need for a convincing story, and there will always be people to appreciate good stories. Although with what seems to be a pandemic-induced shift into the world of online entertainment & OTT’s. This change was inevitable and fast-tracked due to unexpected external factors.
What the future holds for this industry is exciting for both the filmmakers and the audiences. The audiences have the liberty to watch movies across their preferred mediums early on, rather than the conventional long drawn theatrical only way. The studios now have more ways to engage audiences with their content. In addition to the theatrical experience, they can reach more people faster while ensuring they run a profitable business.
We will soon start seeing more movies & studios using the OTT platforms for early releases and the conventional theatre first releases with downstream combinations of other Home Entertainment forms to bring the movie early to the audience on various platforms.
On an alternate note, in the future, we might be in a stage where Artificial Intelligence (AI) could be generating scripts or stories based on user inputs for specific genres. An AI tool could produce numerous scripts for filmmakers to choose from. It is exciting to think of its potential, for example, say in the hands of an ace director like Christopher Nolan with inputs given to the AI tool based on movies like Tenet or Inception.
Post-Pandemic, when life returns to normal, we are likely to see star-studded, big-budget movies directly being released on Netflix or HBO Max, skipping the conventional theatrical release. Many filmmakers have expressed concerns that the rise of OTT may even lead to the death of theatres.
That said, I do not think that the theatres would perish. Theatres were and will always be a social experience to celebrate larger-than-life movies. The number of instances where people go to theatres might reduce since new movies will be offered in the comfort of their homes.
With all this discussion surrounding making profitable movies, with the help of Analytics, Insights & Strategy, why don’t filmmakers and studios stop after making a couple of profitable movies?
The answer is clear, as stated by Walt Disney, one of the brightest minds of the 20th century, “We don’t make movies to make money, we make money to make more movies.”
- The Shawshank Redemption Image: https://www.brightwalldarkroom.com/2019/03/08/shawshank-redemption-1994/
- Godzilla vs. Kong $200 Million Bid:
https://deadline.com/2020/11/godzilla-vs-kong-netflix-hbo-max-talks-box-office-1234622226/ - US OTT Platforms Statistics:
- https://www.statista.com/statistics/1110896/svod-monthly-subscription-cost-us/
- https://www.statista.com/statistics/250937/quarterly-number-of-netflix-streaming-subscribers-in-the-us/
- https://www.statista.com/statistics/258014/number-of-hulus-paying-subscribers/
- https://www.statista.com/statistics/648541/amazon-prime-video-subscribers-usa/
- https://deadline.com/2021/01/hbo-max-streaming-doubles-in-q4-17-million-wonder-woman-1984-at-t-1234681277/
- https://entertainmentstrategyguy.com/2020/11/18/netflix-has-as-many-subscribers-as-disney-and-prime-video-put-together-in-the-united-states-visual-of-the-week/
- https://9to5mac.com/2021/01/20/apple-tv-had-only-3-market-share-in-the-us-last-quarter-netflix-still-in-first-place/